
ГОСТ Р ИСО 9735-1-2012
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
ЭЛЕКТРОННЫЙ ОБМЕН ДАННЫМИ В УПРАВЛЕНИИ, ТОРГОВЛЕ И НА ТРАНСПОРТЕ (EDIFACT)
Синтаксические правила для прикладного уровня (версия 4, редакция 1)
Часть 1
Синтаксические правила, общие для всех частей
Electronic data interchange for administration, commerce and transport (EDIFACT). Application level syntax rules (Syntax version number 4. Syntax release number 1). Part 1. Syntax rules common to all parts
ОКС 35.240.60
Дата введения 2014-01-01
Предисловие
1 ПОДГОТОВЛЕН ЗАО "Проспект" совместно с Ассоциацией автоматической идентификации "ЮНИСКАН/ГС1 РУС" на основе собственного перевода на русский язык англоязычной версии стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 55 "Терминология, элементы данных и документация в бизнес-процессах и электронной торговле"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 20 ноября 2012 г. N 971-ст.
4 Настоящий стандарт идентичен международному стандарту ИСО 9735-1:2002* "Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 1. Синтаксические правила, общие для всех частей" (ISO 9735-1:2002 "Electronic data interchange for administration, commerce and transport (EDIFACT) - Application level syntax rules (Syntax version number: 4, Syntax release number: 1) - Part 1: Syntax rules common to all parts", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные стандарты, сведения о которых приведены в дополнительном приложении ДА
5 ВВЕДЕН ВПЕРВЫЕ
6 ПЕРЕИЗДАНИЕ. Январь 2019 г.
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске ежемесячного информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
Введение
Настоящий стандарт включает в себя правила прикладного уровня для структурирования данных в рамках обмена электронными сообщениями в открытой среде, с учетом требований пакетной или интерактивной обработки. Эти правила утверждены Европейской экономической комиссией Организации Объединенных Наций (UN/ECE) в качестве синтаксических правил электронного обмена данными в управлении, торговле и на транспорте (EDIFACT) и являются частью Справочника по обмену торговыми данными Организации Объединенных Наций (UNTDID), содержащего рекомендации по разработке сообщений пакетного и интерактивного обмена.
_______________
Сокращенное от United Nations Trade Data Interchange Directory.
Настоящий стандарт может использоваться в любых приложениях, но сообщения, для которых применяются указанные правила, могут считаться сообщениями типа EDIFACT, только если они соответствуют рекомендациям и правилам UN/ECE, а также справочникам UNTDID. К сообщениям UN/EDIFACT применимы определенные правила построения сообщений для пакетной или интерактивной обработки. Эти правила содержатся в UNTDID.
Спецификации и протоколы связи не рассматриваются в настоящем стандарте.
Настоящий стандарт идентичен ИСО 9735-1:2002, содержащему правила, общие для всех частей ИСО 9735, а также используемые в этих частях термины и определения.
Базовые синтаксические правила, изложенные в настоящем стандарте, не изменились по сравнению с предыдущей версией ИСО 9735, за исключением того, что была расширена поддержка наборов графических знаков и введены две новые методики (представление "отметок зависимости" и введение служебного знака повтора для поддержки многократных вхождений - "повторов" - автономных и/или составных элементов данных). Обе эти методики используются в других частях текущей версии ИСО 9735 и могут входить в сообщения EDIFACT, составленные с помощью данного международного стандарта.
Кроме того, были введены усовершенствования в заголовки сегментов пакетного обмена, групп и сообщений (UNB, UNG и UNH).
Наборы графических знаков. Вследствие расширения сферы применения ИСО 9735 появилась необходимость добавления всех наборов графических знаков, описанных в частях 1-9 ИСО 8859, методов расширения кодов по ИСО 2022 (с определенными ограничениями на их использование при обмене) и частичного использования методов ИСО/МЭК 10646-1.
Отметки зависимости. Данные отметки предоставляют формальное описание для выражения зависимостей в спецификациях сообщений, сегментов и составных элементов данных EDIFACT.
Повторяющиеся элементы данных. В настоящей версии расширена спецификация предыдущей версии ИСО 9735 для многократных вхождений сообщения в группу или обмен, группы в обмен и сегмента и/или группы сегментов в сообщение. Была предусмотрена дополнительная возможность спецификации повторов автономных и/или составных элементов данных внутри сегмента.
UNB-сегмент заголовка обмена. Данный сегмент был усовершенствован с целью поддержки идентификации номера версии справочника списков служебных кодов, идентификации схемы кодирования знаков и внутренней дополнительной идентификации отправителя и получателя. Кроме того, формат даты, используемый в этом сегменте, был расширен для согласования с требованиями к идентификации дат позднее 2000 года.
UNG-сегмент заголовка группы. Данный сегмент был переименован, а его функция изменена с целью возможного включения сообщений и/или пакетов одного или нескольких типов в группу. В результате некоторые элементы данных, которые на данный момент не нужны, помечены для удаления. Кроме того, формат даты, используемый в этом сегменте, был расширен для согласования с требованиями к идентификации дат позже 2000 года.
UNH-сегмент заголовка сообщения. Данный сегмент был усовершенствован с целью поддержки идентификации подмножества сообщений, связанного руководства по реализации сообщений и связанного сценария.
Предотвращение конфликтов сегментов. Было введено дополнение для предотвращения конфликтов путем применения групп сегментов UGH/UGT. Данная методика должна использоваться в спецификации сообщения, если иным образом невозможно обеспечить однозначную идентификацию каждого сегмента сообщения после его получения.
Идентификация редакции синтаксиса. Введено дополнение, позволяющее идентифицировать конкретные редакции данной версии синтаксиса. Оно упростит публикацию второстепенных изменений стандарта (если они потребуются в будущем).
Комплекс стандартов ИСО 9735 состоит из следующих частей под общим названием "Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1)":
- Часть 1. Синтаксические правила, общие для всех частей;
- Часть 2. Синтаксические правила, специфичные для пакетного ЭОД;
_______________
ЭОД - "электронный обмен данными" соответствует английскому EDI - "electronic data interchange".
- Часть 3. Синтаксические правила, специфичные для интерактивного ЭОД;
- Часть 4. Сообщение синтаксического и служебного уведомления для пакетного ЭОД (тип сообщения - CONTRL);
- Часть 5. Правила защиты для пакетного ЭОД (аутентичность, целостность и неотказуемость источника);
- Часть 6. Сообщение для защищенной аутентификации и защищенного квитирования (тип сообщения - AUTACK);
- Часть 7. Правила защиты для пакетного ЭОД (конфиденциальность);
- Часть 8. Ассоциированные данные в ЭОД;
- Часть 9. Сообщение для управления ключами и сертификатами защиты (тип сообщения - KEYMAN);
- Часть 10. Справочники служебных синтаксических структур.
1 Область применения
Настоящий стандарт определяет общие синтаксические правила для форматирования пакетных и интерактивных сообщений, используемых в обмене между прикладными компьютерными системами. Настоящий стандарт устанавливает термины и определения, используемые во всех частях ИСО 9735.
2 Соответствие стандарту
Для соответствия настоящему стандарту в обязательном элементе данных 0002 (номер версии синтаксических правил) должен использоваться номер версии "4", а в условном элементе данных 0076 (номер редакции синтаксических правил) должен указываться номер редакции "01". Каждый из этих элементов данных входит в сегмент UNB (заголовок обмена). В обменах, в которых продолжает использоваться синтаксис более ранних версий, для различения соответствующих синтаксических правил необходимо указывать следующие номера версий:
- ИСО 9735:1988 - Номер версии синтаксических правил: 1;
- ИСО 9735:1988 (перепечатанный с изменениями в 1990 г.) - Номер версии синтаксических правил: 2;
- ИСО 9735:1988 с Изменением 1:1992 - Номер версии синтаксических правил: 3;
- ИСО 9735:1998 - Номер версии синтаксических правил: 4.
Соответствие стандарту означает, что соблюдены все его требования, включая опции. Если же поддерживаются не все опции, то в любом заявлении о соответствии должно содержаться положение, идентифицирующее опции, по которым декларируется соответствие.
Данные, используемые в обмене, признаются соответствующими настоящему стандарту, если их структура и представление отвечают синтаксическим правилам, определенным в настоящем стандарте.
Устройства, поддерживающие настоящий стандарт, признаются соответствующими ему, если они способны формировать и/или интерпретировать данные, структурированные и представленные в соответствии с требованиями настоящего стандарта.
Соответствие требованиям настоящего стандарта означает соответствие требованиям ИСО 9735-1, ИСО 9735-10 и требованиям как минимум одной из частей ИСО 9735-2 или ИСО 9735-3.
Положения других стандартов, указанных в настоящем стандарте, являются составными элементами критериев соответствия настоящему стандарту.
3 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты. Для датированных ссылок необходимо пользоваться только указанной редакцией. Для недатированных - последней редакцией ссылочных стандартов, включая любые поправки и изменения к ним:
_______________
* Таблицу соответствия национальных стандартов международным см. по ссылке. - .
ISO/IEC 646:1991, Information technology - ISO 7-bit coded character set for information interchange (Информационные технологии. Набор знаков ИСО с 7-битным кодированием для обмена информацией)
ISO/IEC 2022:1994, Information technology - Character code structure and extension techniques (Информационные технологии. Структура кода знаков и методы расширения)
ISO/IEC 2382-1:1993, Information technology - Vocabulary - Part 1: Fundamental terms (Информационные технологии. Словарь. Часть 1. Основные термины)
________________
Заменен на ISO/IEC 2382:2015.
ISO/IEC 2382-4:1999, Information technology - Vocabulary - Part 4: Organization of data (Информационные технологии. Словарь. Часть 4. Организация данных)
________________
Заменен на ISO/IEC 2382-4:2015.
ISO 6093:1985, Information processing - Representation of numerical values in character strings for information interchange (Обработка информации. Представление числовых значений строками знаков для обмена информацией)
ISO/IEC 6429:1992, Information technology - Control functions for coded character sets (Информационные технологии. Функции управления для наборов кодированных знаков)
ISO/IEC 6523-1:1998, Information technology - Structure for the identification of organizations and organization parts - Part 1: Identification of organization identification schemes (Информационные технологии. Структура идентификации организаций и частей организаций. Часть 1. Идентификация схем идентификации организаций)
ISO 7498-2:1989, Information processing systems - Open Systems Interconnection - Basic reference model - Part 2: Security architecture (Системы обработки информации. Взаимосвязь открытых систем. Базовая эталонная модель. Часть 2. Архитектура защиты информации)
ISO/IEC 9594-8:1998, Information technology - Open systems interconnection - The Directory: Authentication framework (Информационные технологии. Взаимосвязь открытых систем. Директория. Система понятий аутентификации)
________________
Заменен на ISO/IEC 9594-8:2017.
ISO 9735-2:2002, Electronic data interchange for administration, commerce and transport (EDIFACT) - Application level syntax rules (Syntax version number: 4, Syntax release number: 1) - Part 2: Syntax rules specific to batch EDI [Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 2. Синтаксические правила, специфичные для пакетного ЭОД]
ISO 9735-3:2002, Electronic data interchange for administration, commerce and transport (EDIFACT) - Application level syntax rules (Syntax version number: 4, Syntax release number: 1) - Part 3: Syntax rules specific to interactive EDI [Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 3. Синтаксические правила, специфичные для интерактивного ЭОД]
ISO 9735-10:2002, Electronic data interchange for administration, commerce and transport (EDIFACT) - Application level syntax rules (Syntax version number: 4, Syntax release number: 1) - Part 10: Syntax service directories [Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 10. Справочники служебных синтаксических структур]
________________
Заменен на ISO 9735-10:2014.
ISO/IEC 10646-1:2000, Information technology - Universal Multiple-Octet Coded Character Set (UCS) - Part 1: Architecture and Basic Multilingual Plane [Информационные технологии. Универсальный многооктетный набор кодированных знаков (UCS). Часть 1. Архитектура и основная многоязычная матрица]
________________
Заменен на ISO/IEC 10646:2003.
ISO/IEC 11770-1:1996, Information technology - Security techniques - Key management - Part 1: Framework (Информационные технологии. Методы защиты. Управление ключами. Часть 1. Структура)
________________
Заменен на ISO/IEC 11770-1:2010.
ITU-T Recommendation F.400/X.400:1999, Message handling system and service overview (рекомендация F.400/X.400:1999 Обзор системы и службы обработки сообщений)
4 Термины и определения
В настоящем стандарте используются следующие термины с соответствующими определениями:
Примечание 1 - Если слово или фраза в определении набрано курсивом, то в данном разделе имеется пункт, в котором приведено определение соответствующего термина.
Примечание 2 - Термины упорядочены по английскому алфавиту.
4.1 набор алфавитных знаков (alphabetic character set): Набор знаков, состоящий из букв и/или идеограмм и, возможно, других графических знаков, кроме цифр.
4.2 набор алфавитно-цифровых знаков (alphanumeric character set): Набор знаков, состоящий из букв, цифр и/или идеограмм и, возможно, других графических знаков.
4.3 асимметричный алгоритм (asymmetric algorithm): Криптографический алгоритм, основанный на использовании пары асимметричных ключей, в которую входит открытый ключ и закрытый ключ.
4.4 атрибут (attribute): Характеристика логического объекта.
4.5 аутентификация (authentication): См. аутентификация источника данных (4.34).
4.6 пакетный ЭОД (batch EDI): Электронный обмен данными, при котором отсутствуют строгие требования к формализованному обмену данными между сторонами с использованием запроса и ответа.
4.7 бизнес (business): Последовательности процессов с четко определенным назначением, предполагающие участие не менее двух организаций, реализуемые путем обмена информацией и направленные на достижение взаимосогласованной цели за некоторый интервал времени.
4.8
сертификат (certificate): Открытый ключ пользователя вместе с некоторой другой информацией, защищенной от подделки цифровой подписью с закрытым ключом органа сертификации, выдавшего эту информацию. [ИСО/МЭК 9594-8:1998, статья 3.3.3] |
4.9
орган сертификации; уполномоченный орган по сертификации (certification authority): Орган, уполномоченный одним или несколькими пользователями создавать и присваивать сертификаты. [ИСО/МЭК 9594-8:1998, статья 3.3.8] |
4.10
путь сертификации (certification path): Упорядоченная последовательность сертификатов объектов в информационном дереве каталога, которая может обрабатываться вместе с открытым ключом начального объекта пути с целью получения конечного объекта пути. [ИСО/МЭК 9594-8:1998, статья 3.3.9] |
4.11
знак (character): Один из набора элементов, используемых для организации, управления или представления данных. [ИСО/МЭК 10646-1:2001, статья 4.6] |
4.12 набор графических знаков (character repertoire): Совокупность графических знаков из набора кодированных знаков, рассматриваемая независимо от кодирования.
4.13 расширение кодов (code extension): Способы кодирования знаков, которые не входят в набор графических знаков из данного набора кодированных знаков.
4.14 кодовый список (code list): Полный набор значений элемента данных для кодированного простого элемента данных.
4.15 справочник кодовых списков (code list directory): Перечень идентифицированных и определенных кодовых списков.
4.16
набор кодированных знаков (coded character set): Набор однозначных правил, определяющих набор знаков и взаимно однозначное соответствие между знаками данного набора и их битовыми комбинациями. [ИСО/МЭК 6429:1992] |
4.17 компонентный элемент данных (component data element): Простой элемент данных, используемый в составном элементе данных.
4.18 разделитель компонентных элементов данных (component data element separator): Служебный знак, который используется для отделения друг от друга компонентных элементов данных, входящих в составной элемент данных.
4.19 составной элемент данных (composite data element): Набор функционально связанных компонентных элементов данных, идентифицированный, обозначенный и структурированный так, как описано в спецификации составного элемента данных.
Примечание - При передаче составной элемент данных является конкретным упорядоченным набором из одного или нескольких компонентных элементов данных согласно спецификации составного элемента данных.
4.20 справочник составных элементов данных (composite data element directory): Перечень идентифицированных и обозначенных составных элементов данных, включающий спецификации составных элементов данных.
4.21 спецификация составного элемента данных (composite data element specification): Описание составного элемента данных из справочника составных элементов данных, включающее положение и статус всех компонентных элементов данных, которые образуют этот составной элемент данных.
4.22 условный (conditional): Тип статуса, используемый в спецификации сообщений, спецификации сегмента или спецификации составного элемента данных для указания на то, что группа сегментов, сегмент, составной элемент данных, автономный элемент данных или компонентный элемент данных используется опционально либо при выполнении соответствующих условий.
4.23
конфиденциальность (confidentiality): Свойство информации быть недоступной и закрытой для неавторизованных индивидуумов, логических объектов или процессов. [ИСО 7498-2:1989, статья 3.3.16] |
4.24
управляющий знак (control character): Знак, назначением которого является изменение формата, управление передачей данных или выполнение других функций управления. Примечание - Управляющий знак может не относиться к графическим знакам, при этом у него может быть графическое представление. [ИСО/МЭК 2382-4:1999, статья 04.04.01] |
4.25
удостоверение (credential): Данные для установления заявленной подлинности логического объекта. [ИСО 7498-2:1989, статья 3.3.17] |
4.26
криптография (cryptography): Дисциплина, охватывающая принципы, средства и методы преобразования данных для сокрытия их информационного содержимого, предотвращения их не обнаруживаемой модификации и/или их несанкционированного использования. [ИСО 7498-2:1989, статья 3.3.20] |
4.27
данные (data): Информация, представленная в повторно интерпретируемом формализованном виде, пригодном для передачи, истолкования или обработки. [ИСО/МЭК 2382-1:1993, статья 01.01.02] |
4.28 элемент данных (data element): Единица данных, описанная в спецификации элемента данных.
Примечание - Есть два класса элементов данных: простые элементы данных и составные элементы данных.
4.29 справочник элементов данных (data element directory): Перечень идентифицированных, обозначенных и определенных простых элементов данных (справочник простых элементов данных) или составных элементов данных (справочник составных элементов данных).
4.30 разделитель элементов данных (data element separator): Служебный знак, используемый для разделения:
- неповторяющихся автономных элементов данных, либо
- составных элементов данных в сегменте, либо
- набора вхождений повторяющегося элемента данных, либо
- пустого набора вхождений повторяющегося элемента данных, где
- набор вхождений повторяющегося элемента данных есть одно или несколько (до заданного максимального числа) вхождений повторяющегося элемента данных в передачу, и
- пустой набор вхождений повторяющегося элемента данных есть повторяющийся элемент данных, для которого в передаче нет ни одного из указанных вхождений.
4.31 спецификация элемента данных (data element specification): Спецификация составного элемента данных в справочнике составных элементов данных либо спецификация простого элемента данных в справочнике простых элементов данных.
4.32 значение элемента данных (data element value): Конкретный экземпляр простого элемента данных, представленный согласно спецификации простого элемента данных, и, если простой элемент данных закодирован, представленный согласно кодовому списку.
4.33
целостность данных (data integrity): Свойство данных не подвергаться несанкционированному изменению или уничтожению. [ИСО 7498-2:1989, статья 3.3.21] |
4.34
аутентификация источника данных (data origin authentication): Подтверждение того, что источник полученных данных совпадает с заявленным. [ИСО 7498-2:1989, статья 3.3.22] |
4.35 представление значений данных (data value representation): Допустимые типы знаков (например, алфавитные или цифровые) и ограничения длины, относящиеся к значениям элемента данных для простого элемента данных.
4.36
десятичный разделитель (decimal mark): Знак для отделения цифр, составляющих целую часть числа, от цифр, составляющих его дробную часть. [ИСО 6093:1985, статья 4.1] |
4.37
дешифрование (decipherment): Процедура, обратная соответствующей процедуре шифрования. [ИСО 7498-2:1989, статья 3.3.23] |
4.38
дешифрация (decryption): См. дешифрование. [ИСО 7498-2:1989, статья 3.3.24] |
4.39 служебные знаки по умолчанию (default service characters): Набор знаков, используемых в качестве служебных знаков, если в строке задания служебных знаков не определен другой набор.
4.40 идентификатор зависимости (dependency identifier): Идентификатор, используемый в отметке зависимости для указания типа зависимости между перечисленными в ней структурными единицами.
4.41 отметка зависимости (dependency note): Отметка, используемая:
a) в спецификации сообщения для указания связей между группами сегментов или сегментами;
b) в спецификации сегмента для указания связей между элементами данных;
c) в спецификации составного элемента данных для указания связей между компонентными элементами данных.
4.42 диалог (dialogue): Двустороннее взаимодействие между инициатором и респондентом в ходе транзакции И-ЭОД.
Примечание - Формально диалог состоит из двух обменов.
4.43
цифровая подпись (digital signature): Дополнительные данные или криптографическое преобразование (см. криптография) какого-либо блока данных, позволяющие получателю блока данных убедиться в подлинности отправителя и целостности блока данных и защитить его от искажения с помощью, например, средств получателя. [ИСО 7498-2:1989, статья 3.3.26] |
4.44 электронный обмен данными; ЭОД (EDI; Electronic Data Interchange): Передача данных электронным способом между двумя компьютерными приложениями при выполнении коммерческих или административных транзакций с использованием согласованного стандарта структурирования транзакции или данных в сообщениях.
4.45
шифрование (encipherment): Криптографическое преобразование данных (см. криптография) для получения шифротекста. [ИСО 7498-2:1989, статья 3.3.27] |
4.46 кодирование (encoding): Представление знака в виде комбинации битов.
4.47
шифрация (encryption): См. шифрование. [ИСО 7498-2:1989, статья 3.3.28] |
4.48 знак показателя степени (exponent mark): Управляющий знак, используемый для указания на то, что знак/знаки, которые следуют за ним, должны интерпретироваться в качестве показателя степени.
Примечание - Знаки "Е" или "е" используются в качестве знака показателя степени.
4.49 фильтрация (filtering): Процедура преобразования октетов с произвольной комбинацией битов в октеты, входящие в набор знаков, который может поддерживаться в рамках используемого синтаксиса.
4.50
графический знак (graphic character): Знак, отличный от управляющего знака, имеющий визуальное представление и обычно генерируемый при письме, печати или отображении. [ИСО/МЭК 2382-4:1999, статья 04.03.01] |
4.51 группа (group): Группа сообщений (одного или нескольких типов сообщений) и/или пакетов (в каждый из которых входит объект), начинающаяся с заголовка группы и заканчивающаяся окончанием группы.
4.52 заголовок группы (group header): Служебный сегмент, который является началом группы и идентифицирует ее.
4.53 окончание группы (group trailer): Служебный сегмент, завершающий группу.
4.54
хеш-функция (hash function): Математическая функция, преобразующая значения из большой (возможно, очень большой) области в меньший диапазон. "Хорошей" считается такая хеш-функция, результаты применения которой к (большому) набору значений в области определения будут равномерно (и предположительно случайным образом) распределены по всему диапазону ее значений. [ИСО/МЭК 9594-8:1998, статья 3.3.14] |
4.55 интерактивный ЭОД; И-ЭОД (Interactive EDI; I-EDI): Обмен заранее определенными и структурированными данными в ходе диалога в соответствии с синтаксисом ИСО 9735-1 и ИСО 9735-3 с соблюдением временного режима между двумя взаимодействующими процессами для некоторых целей бизнеса.
4.56 транзакция И-ЭОД (I-EDI transaction): Реализация сценария, состоящего из одного или нескольких диалогов.
4.57 идентификатор (identifier): Знак или группа знаков, используемых для идентификации или обозначения единицы данных и, возможно, для указания на конкретные характеристики этих данных.
4.58 идеограмма (ideogram): В естественном языке - графический знак, представляющий понятие и связанные с ним фонетические элементы.
Пример - Китайский иероглиф или значок из японской азбуки кандзи.
4.59 инициатор (initiator): Приложение, начинающее диалог и/или транзакцию И-ЭОД.
4.60 целостность (integrity): См. целостность данных.
4.61 обмен (interchange): Последовательность сообщений и/или пакетов одного или нескольких типов, начинающаяся с заголовка обмена (или строки задания служебных знаков, если она используется) и заканчивающаяся окончанием обмена.
4.62 заголовок обмена (interchange header): Служебный сегмент, который служит началом обмена и однозначно идентифицирует его.
4.63 окончание обмена (interchange trailer): Служебный сегмент, завершающий обмен.
4.64
ключ (key): Последовательность символов, управляющая операциями шифрования и дешифрования. [ИСО 7498-2:1989, статья 3.3.32] |
4.65 обязательный (mandatory): Тип статуса, используемый в спецификации сообщения, спецификации сегмента или спецификации составного элемента данных для указания на то, что группа сегментов, сегмент, составной элемент данных, автономный элемент данных или компонентный элемент данных должен использоваться как минимум один раз.
4.66 сообщение (message): Идентифицированный, обозначенный и структурированный набор функционально связанных сегментов, обеспечивающий выполнение требований для конкретного типа транзакции (например, выставления счета) согласно спецификации сообщения; сообщение начинается с заголовка сообщения и заканчивается окончанием сообщения.
Примечание - При передаче сообщение является конкретным упорядоченным набором сегментов согласно спецификации сообщения.
4.67 тело сообщения (message body): Идентифицированный, обозначенный и структурированный набор функционально связанных сегментов, обеспечивающий выполнение требований для конкретного типа транзакции (например, выставление счета) согласно спецификации сообщения и не включающий заголовок сообщения и окончание сообщения.
4.68 справочник сообщений (message directory): Перечень идентифицированных и обозначенных сообщений, каждое из которых входит вместе со своей спецификацией сообщения.
4.69 заголовок сообщения (message header): Служебный сегмент, который служит началом сообщения и однозначно идентифицирует его.
4.70 спецификация сообщения (message specification): Описание сообщения в справочнике сообщений, включающее спецификацию положения, статуса и максимального числа вхождений сегментов и групп сегментов, составляющих данное сообщение.
4.71 окончание сообщения (message trailer): Служебный сегмент, завершающий сообщение.
4.72 тип сообщения (message type): Код, идентифицирующий тип сообщения.
4.73
неотказуемость источника (non-repudiation of origin): Вариант услуги защиты, позволяющий отправителю сообщения предоставлять получателю (получателям) неопровержимое подтверждение источника сообщения и целостности его содержимого. Данная услуга защищает от любых попыток отправителя позже отказаться от сообщения или оспорить целостность его содержимого. Неотказуемость источника обеспечивается для получателя или получателей сообщения для каждого сообщения отдельно с помощью асимметричных методов шифрования. [ITU-T F.400/X.400, Поправка 1] |
4.74
набор цифровых знаков (numeric character set): Набор знаков, состоящий из цифр и, возможно, управляющих знаков или специальных знаков, но не букв. [ИСО/МЭК 2382-4:1999, статья 04.01.04] |
4.75 объект (object): Последовательность битов, объединенных в байты (октеты), которая может быть ассоциирована с сообщением EDIFACT.
4.76 заголовок объекта (object header): Служебный сегмент, который служит началом объекта и однозначно идентифицирует его.
4.77 окончание объекта (object trailer): Служебный сегмент, завершающий объект.
4.78
организация (organization): Уникальная схема реализации полномочий, в рамках которой с определенной целью действуют или призваны действовать отдельные лица или лицо. [ИСО/МЭК 6523-1:1998, статья 3.1] |
4.79 пакет (package): Объект вместе с его сегментами заголовка и окончания.
4.80 отношение "родитель-потомок" (parent-child relationship): Отношение между двумя логическими объектами (сущностями), один из которых ("потомок") содержится внутри другого ("родителя") и непосредственно подчинен ему.
4.81 идентификатор положения (position identifier): Идентификатор, используемый в отметке зависимости для идентификации логического объекта (группы сегментов, сегмента или элемента данных) по его положению внутри родительского логического объекта.
4.82
закрытый ключ; личный ключ (private key): Ключ из пары ключей пользователя, который известен только данному пользователю (в криптографических системах с открытым ключом). [ИСО/МЭК 9594-8:1998, статья 3.3.19] |
4.83
открытый ключ; ключ общего пользования (public key): Ключ из пары ключей пользователя, являющийся общеизвестным (в криптографических системах с открытым ключом). [ИСО/МЭК 9594-8:1998, статья 3.3.18] |
4.84 квалификатор (qualifier): Простой элемент данных, значение которого, извлеченное из кодового списка, конкретизирует назначение другого элемента данных или сегмента.
4.85 знак освобождения (release character): Знак, указывающий на то, что непосредственно следующий за ним знак должен передаваться приложению в том виде, в каком он был принят.
_______________
Знак освобождения предназначен для однократного освобождения следующего за ним служебного знака от управляющей функции, закрепленной в сегменте UNA или по умолчанию.
4.86 повторяющийся элемент данных (repeating data element): Составной элемент данных или автономный элемент данных с числом вхождений в спецификацию сегмента, превышающим единицу.
4.87 разделитель повторов (repetition separator): Служебный знак, используемый для отделения друг от друга последовательных вхождений повторяющегося элемента данных.
4.88 респондент (responder): Приложение, отвечающее на запросы инициатора.
4.89 сценарий (scenario): Формальное описание совокупности мероприятий, объединенных единой бизнес-целью.
4.90
секретный ключ (secret key): Ключ в системах симметричной криптографии, пригодный для использования только некоторыми заданными логическими объектами. [ИСО/МЭК 11770-1:1996, статья 3.18] |
4.91 сегмент (segment): Идентифицированный, обозначенный и структурированный набор функционально связанных составных элементов данных и/или автономных элементов данных, описанных в спецификации сегмента; каждый сегмент начинается с тега сегмента и заканчивается терминатором сегмента.
Примечание - При передаче сегмент является конкретным упорядоченным набором из одного или нескольких составных элементов данных и/или автономных элементов данных согласно спецификации сегмента и синтаксическим правилам-передачи.
4.92 справочник сегментов (segment directory): Перечень идентифицированных и обозначенных сегментов, включающий соответствующие спецификации сегментов.
4.93 группа сегментов (segment group): Идентифицированный иерархический набор сегментов и/или групп сегментов внутри сообщения.
4.94 спецификация сегмента (segment specification): Описание сегмента в справочнике сегментов, включающее спецификацию положения, статуса и максимального числа вхождений элементов данных, составляющих этот сегмент.
4.95 тег сегмента (segment tag): Простой элемент данных, однозначно идентифицирующий сегмент путем ссылки на справочник сегментов.
4.96 терминатор сегмента (segment terminator): Служебный знак, указывающий на конец сегмента.
4.97 служебный знак (service character): Знак, зарезервированный для использования в синтаксисе; служебными знаками являются разделитель компонентных элементов данных, разделитель элементов данных, знак освобождения, разделитель повторов и терминатор сегмента.
4.98 служебный составной элемент данных (service composite data element): Составной элемент данных, используемый в служебных сегментах.
Примечание - В спецификацию служебных составных элементов данных входят только служебные простые элементы данных.
4.99 служебный элемент данных (service data element): Служебный простой элемент данных или служебный составной элемент данных.
4.100 служебное сообщение (service message): Сообщение, используемое для обмена служебной информацией, которая относится к использованию синтаксических правил EDIFACT или к защите информации.
Примечание - В спецификацию служебного сообщения входят только служебные сегменты.
4.101 служебный сегмент (service segment): Сегмент, используемый:
a) в служебных сообщениях;
b) для управления передачей данных.
Примечание - В спецификацию служебного сегмента входят только служебные составные элементы данных и/или служебные простые элементы данных.
4.102 служебный простой элемент данных (service simple data element): Простой элемент данных, используемый только в служебных сегментах и/или в служебных составных элементах данных.
4.103 строка задания служебных знаков (service string advice): Необязательная строка знаков, используемая в начале обмена для задания служебных знаков, используемых в обмене.
4.104 простой элемент данных (simple data element): Элемент данных, содержащий единственное значение элемента данных.
Примечание - Простые элементы данных используются в двух случаях: в составных элементах данных (в качестве компонентных элементов данных) и в сегментах вне составных элементов данных (в качестве автономных элементов данных).
4.105 справочник простых элементов данных (simple data element directory): Перечень идентифицированных и обозначенных простых элементов данных, включающий соответствующие спецификации простых элементов данных.
4.106 спецификация простого элемента данных (simple data element specification): Набор атрибутов, описывающих простой элемент данных в справочнике простых элементов данных.
4.107
специальный знак (special character): Графический знак, не являющийся буквой, цифрой или пробелом и, как правило, не являющийся идеограммой. [ИСО/МЭК 2382-4:1999, статья 04.03.12] |
4.108 автономный элемент данных (stand-alone data element): Простой элемент данных внутри сегмента, не входящий в составной элемент данных.
4.109 статус (status): Атрибут, относящийся к сегменту, группе сегментов, составному элементу данных или простому элементу данных и определяющий правила присутствия или отсутствия сегмента либо элемента данных в сообщении.
Примечание - Есть два типа статуса: условный и обязательный.
4.110
строка (string): Последовательность однотипных элементов, таких как знаки, рассматриваемая как одно целое. [ИСО/МЭК 2382-4:1999, статья 04.05.01] |
4.111 симметричный алгоритм (symmetric algorithm): Криптографический алгоритм с использованием одного и того же значения ключа для шифрования и дешифрования либо для аутентификации и проверки достоверности.
4.112
угроза (threat): Потенциальное нарушение защиты. [ИСО 7498-2:1989, статья 3.3.55] |
4.113 передача (transfer): Посылка информации от одного партнера другому.
4.114 пусковой сегмент (trigger segment): Сегмент, который является началом группы сегментов.
5 Служебные знаки
5.1 Общие положения
Служебными знаками являются: разделитель компонентных элементов данных, разделитель элементов данных, знак освобождения, разделитель повторов и терминатор сегмента.
Как определено в разделе 7, разделитель компонентных элементов данных, разделитель элементов данных, разделитель повторов и терминатор сегмента служат для задания границ различных синтаксических структур.
Знак освобождения позволяет передать традиционное значение некоторого знака, который в противном случае интерпретировался бы в качестве служебного. Знак, непосредственно следующий за знаком освобождения, в обмене, не должен считаться служебным знаком.
Знаки освобождения не учитываются при вычислении длины значения элемента данных.
Примечание - При использовании служебных знаков по умолчанию, определенных в 5.2, передаваемый элемент данных 10?+10=20 при получении будет интерпретироваться как 10+10=20. Вопросительный знак в значении элемента данных представляется при передаче в виде ??.
5.2 Служебные знаки, используемые по умолчанию
Служебные знаки, используемые по умолчанию в настоящем стандарте, приведены в таблице 1.
Таблица 1 - Служебные знаки, используемые по умолчанию
Название | Графическое представление | Назначение |
Двоеточие | : | Разделитель компонентных элементов данных |
Знак "плюс" | + | Разделитель элементов данных |
Вопросительный знак | ? | Знак освобождения |
Звездочка | * | Разделитель повторов |
Апостроф | ' | Терминатор сегмента |
5.3 Строка задания служебных знаков UNA
Условная строка задания служебных знаков (UNA) дает возможность задания служебных знаков, используемых в обмене (см. приложение А). Строка UNA должна использоваться, если служебные знаки отличаются от заданных по умолчанию (см. 5.2). Ее использование не обязательно, если они одни и те же.
При использовании данной строки она должна следовать непосредственно перед сегментом заголовка обмена.
6 Наборы графических знаков
Все знаки от строки задания служебных знаков (если она используется) до составного элемента данных S001 "Идентификатор синтаксиса" заголовка обмена должны иметь кодировку, в соответствии с базовой кодовой таблицей ИСО/МЭК 646.
Набор графических знаков, используемый в ходе обмена, должен определяться значением кода элемента данных 0001 в элементе S001 "Идентификатор синтаксиса" заголовка обмена (см. ИСО 9735-10). Данный набор графических знаков не используется для представления объектов и/или шифрованных данных.
По умолчанию для конкретного набора графических знаков должен использоваться способ кодирования, определяемый спецификацией соответствующего набора знаков.
Если вариант по умолчанию не используется, то должно использоваться значение кода элемента данных 0133 "Кодирование знаков, кодированное" из заголовка обмена.
Расширение кодов (см. ИСО/МЭК 2022) допустимо для использования в обмене только после составного элемента данных S001 "Идентификатор синтаксиса" заголовка обмена.
Указанный метод расширения кодов и поддерживаемые графические знаки должны использоваться только для элементов данных на естественном языке (текстовые данные), представленных в виде букв или букв и цифр.
Данный метод неприменим, например, для:
- тегов сегментов, или
- служебных знаков, или
- элементов данных, представляемых в виде цифр.
Знаки, используемые для указания на расширение кодов, не должны учитываться при вычислении длины элемента данных и не должны использоваться в качестве служебных знаков.
При вычислении длины элемента данных каждый графический знак считается за один знак независимо от числа байтов/октетов, которые требуются для его кодирования.
7 Синтаксические структуры
7.1 Общие положения
Определения, приведенные в данном разделе, задают логические синтаксические структуры. Правила использования этих структур определены в разделе 8.
7.2 Структура обмена
Обмен должен начинаться с передачи строки задания служебных знаков либо заголовка обмена, определяться заголовком обмена, должен заканчиваться окончанием обмена и включать не менее одной группы, одного сообщения или одного пакета. В обмене может использоваться несколько групп, сообщений и/или пакетов, и все они идентифицируются своими заголовками и заканчиваются своими окончаниями. Сообщения внутри обмена или внутри одной группы могут быть одного типа или разных типов.
В обмен могут входить только:
- сообщения, либо
- пакеты, либо
- сообщения и пакеты, либо
- группы, содержащие сообщения, либо
- группы, содержащие пакеты, либо
- группы, содержащие сообщения и пакеты.
7.3 Структура группы
Группа - условная конструкция, расположенная между заголовком обмена и его окончанием, которая состоит из одного или нескольких сообщений и/или пакетов.
Группа должна начинаться с заголовка группы, который служит для ее идентификации, должна завершаться окончанием группы и включать как минимум одно сообщение или один пакет.
7.4 Структура сообщения
Сообщение состоит из упорядоченного набора сегментов (см. приложение В). Сегменты могут объединяться в группы. Положение, статус и максимальное число вхождений каждого сегмента должны быть установлены в спецификации сообщения.
Статус конкретного сегмента в спецификации сообщения может быть обязательным либо условным.
Спецификация сообщения должна гарантировать однозначную идентификацию каждого сегмента при его получении по тегу данного сегмента (или по тегу и по идентификаторам группы сегментов, ограниченной сегментами UGH и UGT во избежание конфликтов) и его местоположению в переданном сообщении. Идентификация не должна зависеть от статуса сегмента и максимального числа его вхождений.
Сообщение должно начинаться с заголовка сообщения, который служит для его идентификации, завершаться окончанием сообщения и должно включать как минимум один дополнительный сегмент.
7.5 Структура группы сегментов
Группа сегментов состоит из упорядоченного набора сегментов: пускового сегмента и одного или нескольких сегментов или их групп. Пусковой сегмент должен быть первым в группе сегментов, иметь статус обязательного и максимальное число вхождений, равное единице. Положение, статус и максимальное число вхождений каждой группы сегментов должны быть установлены в спецификации сообщения.
В группу сегментов могут входить одна или несколько групп сегментов, зависимых от нее. Группу сегментов, входящую в другую группу и непосредственно подчиненную ей, называют потомком, а группу сегментов, в которую она входит, - родителем.
Статус конкретной группы сегментов в спецификации сообщения может быть обязательным либо условным.
7.6 Структура сегмента
Сегмент состоит из упорядоченного набора автономных элементов данных и/или составных элементов данных, каждый из которых может повторяться, если это указано в спецификации сегмента. Положение, статус и максимальное число вхождений каждого автономного или составного элемента данных внутри сегмента должны быть заданы в спецификации этого сегмента. Сегмент должен начинаться с тега сегмента, который служит для его идентификации и содержит ссылку на конкретную спецификацию сегмента. Кроме тега сегмента, в сегменте должен быть по крайней мере один элемент данных.
Статус конкретного элемента данных в спецификации сегмента может быть обязательным либо условным.
7.7 Структура тега сегмента
Тег сегмента является простым элементом данных.
Теги сегментов, начинающиеся с буквы "U" (например, UNB или UIH), зарезервированы для служебных сегментов.
7.8 Структура составного элемента данных
Составной элемент данных состоит из упорядоченного набора двух компонентных элементов данных или более. Положение, статус и максимальное число вхождений каждого компонентного элемента данных внутри составного элемента данных должны быть заданы в спецификации этого составного элемента данных.
Статус конкретного компонентного элемента данных в спецификации составного элемента данных может быть обязательным либо условным.
7.9 Структура простого элемента данных
Простой элемент данных содержит одно значение элемента данных.
Простые элементы данных используются либо в качестве автономных элементов данных, либо в качестве компонентных элементов данных. Автономный элемент данных входит в часть сегмента, не принадлежащую составному элементу данных. Компонентный элемент данных содержится внутри составного элемента данных.
Представление значения данных каждого простого элемента данных должно быть определено в спецификации элемента данных.
7.10 Структура пакета
Пакет должен начинаться с заголовка объекта, который служит для его идентификации, завершаться окончанием объекта и содержать один объект.
8 Включение и исключение
8.1 Общие положения
Правила данного раздела должны применяться при подготовке сообщения к передаче. Согласно этим правилам группы сегментов, сегменты, элементы данных и знаки внутри значения элемента данных должны присутствовать или отсутствовать при определенных обстоятельствах.
8.2 Определение присутствия
Простой элемент данных считается присутствующим, если его значение включает как минимум один знак.
Составной элемент данных считается присутствующим, если присутствует как минимум один из его компонентных элементов данных.
Сегмент считается присутствующим, если присутствует его тег.
Группа сегментов считается присутствующей, если присутствует ее пусковой сегмент.
8.3 Включение групп сегментов
Обязательная группа сегментов, не содержащаяся внутри другой группы сегментов, всегда должна присутствовать.
Обязательная группа сегментов, являющаяся потомком, должна присутствовать, если присутствует ее родительская группа сегментов.
Однократное вхождение группы сегментов, имеющей статус обязательной группы, достаточно для выполнения требования обязательного присутствия.
8.4 Исключение групп сегментов
Если группа сегментов исключена, все ее сегменты и любые зависящие группы сегментов внутри нее также считаются исключенными независимо от их статуса.
8.5 Включение сегментов
Сегменты должны следовать в порядке, установленном в спецификации сообщения.
Каждый сегмент должен заканчиваться терминатором сегмента.
Обязательный сегмент, не входящий в группу сегментов, всегда должен присутствовать.
Обязательный сегмент, входящий в группу сегментов, должен присутствовать, если присутствует данная группа сегментов.
Однократное вхождение сегмента, имеющего статус обязательного, достаточно для выполнения требования обязательного присутствия.
Например, если в определение обязательного сегмента с тегом АВС входят только условные элементы данных и данные для этих элементов отсутствуют в момент передачи, указанный сегмент должен быть передан в виде АВС'.
8.6 Исключение сегментов
Условный сегмент, в котором присутствует лишь его тег, должен быть опущен.
8.7 Включение элементов данных
Элементы данных должны следовать в порядке, заданном в спецификации сегмента.
Соседние неповторяющиеся элементы данных одного сегмента должны отделяться друг от друга разделителем элементов данных.
Соседние вхождения одного и того же повторяющегося элемента данных должны отделяться друг от друга разделителем повторов.
Соседние компонентные элементы данных одного составного элемента данных должны отделяться друг от друга разделителем компонентных элементов данных.
Обязательный автономный элемент данных сегмента должен присутствовать, если присутствует сам сегмент.
Обязательный составной элемент данных сегмента должен присутствовать, если присутствует сам сегмент.
Обязательный компонентный элемент данных составного элемента данных должен присутствовать, если присутствует сам составной элемент данных.
Однократное вхождение повторяющегося элемента данных, имеющего статус обязательного, достаточно для выполнения требования обязательного присутствия.
8.8 Исключение элементов данных
8.8.1 Общие положения
На рисунках 1-6 Tag есть тег сегмента, DE - составной или автономный элемент данных, а СЕ- компонентный элемент данных. Для них используются служебные знаки по умолчанию.
8.8.2 Исключение составных и автономных элементов данных
Если неповторяющийся составной или автономный элемент данных опускается, а за ним в том же сегменте следует другой составной или автономный элемент данных, то на место пропуска элемента должен указывать сохраненный разделитель элементов данных, который обычно следует за этим элементом. Данное правило применимо и в том случае, если опускаются все вхождения повторяющегося элемента данных.
|

Рисунок 1 - Исключение неповторяющихся элементов данных в сегменте
Если один или несколько составных или автономных элементов данных опускаются в конце сегмента, то разделители, которые следуют за ними, должны быть также опущены.
|

Рисунок 2 - Исключение неповторяющихся элементов данных в конце сегмента
8.8.3 Исключение компонентных элементов данных
Если в составном элементе данных опускается один компонентный элемент данных, за которым в том же составном элементе следует еще один компонентный элемент данных, то на место пропуска элемента должен указывать сохраненный разделитель компонентных элементов данных, который обычно следует за этим элементом.
|
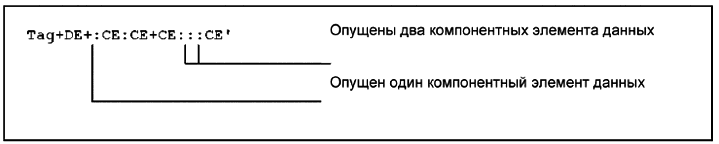
Рисунок 3 - Исключение компонентных элементов данных в составном элементе данных
Если один или несколько компонентных элементов данных опускаются в конце составного элемента данных, то разделители компонентных элементов данных, которые следуют за ними, также должны быть опущены.
|

Рисунок 4 - Исключение компонентных элементов данных в конце составного элемента данных
8.8.4 Исключение компонентных элементов данных, входящих в повторяющийся составной элемент данных
Место вхождения в повторяющийся составной элемент данных может быть важным, например, при передаче массива данных.
В данном случае, если один компонентный элемент данных повторяющегося составного элемента данных опускается, а за ним следует другой компонентный элемент данных того же повторяющегося составного элемента данных, то на место пропуска элемента должен указывать сохраненный разделитель повторов, который обычно следует за этим компонентным элементом данных.
|

Рисунок 5 - Исключение вхождений в повторяющийся элемент данных
Если один или несколько компонентных элементов данных, входящих в повторяющийся составной элемент данных опускаются в конце, то разделители повторов, которые следуют за ними, также должны быть опущены.
|

Рисунок 6 - Исключение вхождений в конце повторяющегося элемента данных
9 Удаление знаков в элементах данных
9.1 Общие сведения
В элементах данных переменной длины незначащие знаки должны быть удалены (т.е. опущены при передаче), а значащие - сохранены.
9.2 Незначащие знаки
В числовых элементах данных переменной длины должны быть удалены нулевые старшие разряды. Тем не менее один нулевой знак до десятичного разделителя может быть оставлен. В буквенных и буквенно-цифровых элементах данных переменной длины должны быть удалены пробелы в конце этих элементов.
9.3 Значащие нули
Информативные нули не должны удаляться. Нуль может быть информативным, например, при передаче данных о температуре или налоговой ставке. Нули после десятичного разделителя могут быть информативными в случае, если необходимо передать информацию о точности.
9.4 Значащие пробелы
Значащими могут быть начальные пробелы и пробелы внутри. Значащие пробелы не должны удаляться.
Значение элемента данных, состоящее из одних пробелов (или одного пробела), недопустимо.
10 Представление числовых значений элементов данных
Для соответствия требованиям настоящего стандарта для числовых значений элементов данных может использоваться любое представление, определенное в ИСО 6093 (в котором исключены разделители триад), со следующими оговорками:
- кодировка, указанная в ИСО/МЭК 646, не является обязательной;
- для числовых полей переменной длины действуют правила удаления знаков (см. раздел 9);
- знаки "пробел" и "плюс" недопустимы;
- при вычислении длины числового значения элемента данных не должны учитываться знаки "минус" (-), десятичный разделитель (точка или запятая), а также знак показателя степени ("Е" или "е") и сам показатель степени;
- десятичный разделитель передается, только если за ним следует хотя бы одна цифра.
Для представления десятичного разделителя в любом числовом значении допустимо использовать точку или запятую.
Пример - Использование десятичных разделителей:
Допустимо (точка): 2 и 2.00 и 0.5 и .5
Недопустимо (точка): 1. и 0. и .
Допустимо (запятая): 2 и 2,00 и 0,5 и ,5
Недопустимо (запятая): 1, и 0, и ,
11 Отметки зависимости
11.1 Общие положения
Для выражения отношений в сообщении, спецификации сегмента или составном элементе данных должны по необходимости использоваться отметки зависимости.
В отметке зависимости определяется список из двух или более логических объектов (каждый из которых может быть группой сегментов, сегментом, составным элементом данных, автономным элементом данных или компонентным элементом данных).
Один логический объект может быть включен в несколько отметок зависимости.
11.2 Отметки зависимости в спецификации сообщения
Отметки зависимости в спецификации сообщения используются для описания отношений между сегментами, между группами сегментов либо между сегментами и группами сегментов. Эти логические объекты должны быть на одном уровне иерархии внутри одной родительской структуры.
11.3 Отметки зависимости в спецификации сегмента
Отметки зависимости в спецификации сегмента используются для описания отношений между автономными элементами данных, между автономными элементами данных и составными элементами данных либо между составными элементами данных. Эти логические объекты должны быть в одном сегменте.
Отметки зависимости не должны использоваться для описания отношений между автономными элементами данных и компонентными элементами данных либо между составными элементами данных и компонентными элементами данных.
11.4 Отметки зависимости в спецификации составного элемента данных
Отметки зависимости в спецификации составного элемента данных используются для описания отношений между компонентными элементами данных. Эти логические объекты должны быть в одном составном элементе данных.
11.5 Система обозначений для отметок зависимости
Обозначение отметки зависимости состоит из идентификатора зависимости, за которым в скобках следует список идентификаторов положения, разделенных запятыми, например, D3 (030, 060, 090). Идентификатор положения ссылается на логический объект по номеру его положения в родительской структурной единице. Идентификатор зависимости определяет тип зависимости между логическими объектами в списке.
В списке должно быть не менее двух идентификаторов положения. Их порядок в данном списке может отличаться от порядка, определяемого их значением.
Описание идентификаторов зависимости:
D1 ОДИН И ТОЛЬКО ОДИН
В списке должен быть один и только один логический объект.
D2 ВСЕ ИЛИ НИ ОДНОГО
Если логический объект присутствует в списке, в нем должны быть и все остальные.
D3 ОДИН ИЛИ БОЛЕЕ
В списке должно быть не менее одного логического объекта.
D4 ОДИН ИЛИ НИ ОДНОГО
В списке должно быть не более одного логического объекта.
D5 ЕСЛИ ПЕРВЫЙ, ТО ВСЕ
Если в списке есть первый логический объект, то в нем должны быть и все остальные. Он не обязан быть в списке, если в нем есть один или несколько логических объектов, не заявленных в качестве первого.
D6 ЕСЛИ ПЕРВЫЙ, ТО НЕ МЕНЕЕ ОДНОГО ЕЩЕ
Если в списке есть первый логический объект, то в нем должен быть как минимум еще один логический объект. Первый логический объект не обязан быть в списке, если в нем есть один или несколько логических объектов, не заявленных в качестве первого.
D7 ЕСЛИ ПЕРВЫЙ, ТО НИ ОДИН ИЗ ДРУГИХ
Если в списке есть первый логический объект, то в нем не может быть других логических объектов.
12 Предотвращение конфликтов сегментов
Группа сегментов UGH/UGT должна использоваться в спецификации сообщения, если после получения сообщения невозможно гарантировать однозначную идентификацию каждого сегмента, исходя из тегов и положений сегментов в переданном сообщении (см. приложение С).
В данном случае группа сегментов, из-за которой однозначная идентификация была невозможной, окружается группой сегментов UGH/UGT.
В группе сегментов UGH/UGT первым должен быть обязательный сегмент UGH, для которого должно быть задано максимальное число вхождений, равное единице. Последним в этой группе должен быть также обязательный сегмент UGT с тем же максимальным числом вхождений.
В качестве номера группы сегментов UGH/UGT в спецификации сообщений должно быть задано значение элемента данных 0087 "Идентификатор группы сегментов для предотвращения коллизий".
Максимальное число вхождений группы сегментов UGH/UGT должно быть равно единице, а задаваемый для нее обязательный либо условный статус должен совпадать со статусом группы сегментов, которую она окружает.
Если условная служебная группа сегментов UGH/UGT окружает условную группу в структуре сообщения, которая может привести к конфликту, то группа UGH/UGT должна передаваться только в том случае, если для окружаемой ею группы имеются данные.
13 Идентификация редакции синтаксиса
Для различения новых редакций одной версии синтаксиса должен использоваться идентификатор синтаксиса Syntax (составной элемент данных S001), входящий в сегменты заголовка обмена UNB или сегменты заголовка интерактивного обмена UIB (см. приложение D).
Приложение А
(обязательное)
Строка задания служебных знаков (UNA)
Строка задания служебных знаков должна начинаться со знаков верхнего регистра UNA, за которыми следуют шесть знаков в описанном ниже порядке. Знак пробела не может использоваться в позициях 010, 020, 040, 050 и 060. Ни один из знаков не должен повторяться в строке UNA.
POS | REP | S | Наименование | Замечания |
010 | an1 | М | COMPONENTDATAELE- | |
020 | an1 | М | DATAELEMENTSEPARATOR | |
030 | an1 | М | DECIMAL MARK | Получатель должен игнорировать знак, передаваемый в данной позиции. Она сохранена для обеспечения совместимости с ранними версиями синтаксиса |
040 | an1 | М | RELEASECHARACTER | |
050 | an1 | М | REPETITION SEPARATOR | |
060 | an1 | М | SEGMENT TERMINATOR | |
Обозначение | ||||
POS | Трехразрядный порядковый номер знака в служебной строке | |||
REP | Представление знака служебной строки | |||
S | Статус знака служебной строки | |||
Наименование | Наименование знака из строки задания служебных знаков | |||
Замечания | Дополнительные замечания | |||
Приложение В
(справочное)
Порядок сегментов и групп сегментов в сообщении
В.1 Общие положения
Последовательность сегментов, используемых в сообщении, определяется таблицей сегментов сообщения (в соответствии с порядком ее строк).
Сегменты в этой таблице представлены тегами. Для указания требования включения сегмента в сообщение, т.е. статуса сегмента, для обязательного включения используется английская буква "М", а для условного - английская буква "С". Число возможных вхождений сегмента в каждый экземпляр сообщения указывается сразу после этой буквы. Далее могут следовать любые связанные с сегментом идентификаторы отметок зависимости.
На группы сегментов в таблице сегментов сообщения указывают их номера. Для указания требования включения группы сегментов в сообщение, т.е. ее статуса, для обязательного включения используется английская буква "М", а для условного - английская буква "С". Число возможных вхождений группы сегментов в каждый экземпляр сообщения указывается сразу после этой буквы. Далее могут следовать любые связанные с группой идентификаторы отметок зависимости.
________________
* Текст документа соответствует оригиналу. - .
В.2 Группы сегментов
Несколько сегментов можно объединять в группы, как показано на рисунке В.1. Пусковой сегмент каждой группы сегментов следует в таблице сообщения сразу за индикатором группы сегментов (Группа сегментов 1, Группа сегментов 2 и т.д.). Далее последовательно перечисляются все остальные сегменты группы, и последний сегмент помечается ограничительными линиями, определяющими границы группы сегментов.
В группу сегментов может входить другая зависимая группа или группы сегментов (например, в Группу сегментов 2 на рисунке ниже входит зависимая Группа сегментов 3). Как видно из рисунка, сегмент может закрывать две сегментные группы (или большее их число), на что указывают ограничительные линии группы сегментов (см. сегмент LLL на рисунке).
На приведенном ниже рисунке Группа сегментов 2 является родителем для Группы сегментов 3, а Группа сегментов 3 - родителем для Группы сегментов 4.
|

Обозначение
POS - | порядковый номер позиции сегмента или группы сегментов в сообщении (с шагом 10 для возможности корректировок структуры сообщения в будущем); |
TAG - | тег сегмента в сообщении; |
Name - | наименование сегмента в сообщении; |
S - | статус (сегмента или группы сегментов), М - обязательный, С - условный; |
R - | максимальное число вхождений сегмента или группы сегментов; |
Notes - | номер примечания. |
Рисунок В.1 - Пример таблицы сегментов сообщения
Примечание 1 - Примером компоновки/задания порядка сегментов может быть такая последовательность (Группа сегментов 1 входит дважды, остальные группы - один раз, а для повторяющихся сегментов показано лишь одно включение):
Uxx,AAA,BBB,CCC,DDD,EEE,FFF,GGG,DDD,EEE,FFF,GGG,HHH,lll,JJJ,KKK,LLL,...Uxx.
Примечание 2 - На практике заголовок сообщения "Uxx" в таблице и в строке сегментов имел бы вид "UNH" для пакетного ЭОД и "UIH" - для интерактивного ЭОД, а окончание сообщения "Uxx" - вид "UNT" для пакетного ЭОД и "UIT" - для интерактивного ЭОД.
Примечание 3 - Отметки зависимости на уровне сообщений (см. примечание 1 к рисунку В.1) можно задавать в таблице сегментов сообщения (которая в UN/EDIFACT является частью спецификации сообщения).
Приложение С
(справочное)
Использование группы сегментов UGH/UGT для предотвращения конфликтов
С.1 Введение
В данном приложении описано использование группы сегментов UGH/UGT для предотвращения конфликтов между сегментами. Данную методику следует использовать только в случае, если все альтернативные подходы оказались безуспешными.
С.2 Проблема
Пример 1 -
|
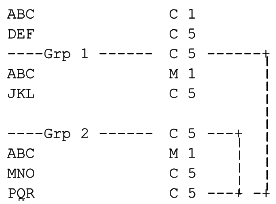
В приведенном выше примере показана структура сообщения с пятью сегментами в семи позициях. Сегмент АВС используется в трех разных позициях.
Последовательность данных могла бы выглядеть следующим образом:
ABC+...'DEF+...'ABC+...'JKL+...'ABC+...'MNO+...'PQR+...'ABC+...'.
Из примера 1 видно, что возникает конфликт сегментов, так как неясно, является ли первый сегмент АВС автономным или он есть начало группы Grp 1. Для сегмента АВС после сегмента JKL также наблюдается неоднозначность: он может быть началом Grp 2 либо началом Grp 1.
Использование группы сегментов UGH/UGT позволяет устранить данный конфликт. Для правильного включения групп UGH/UGT ими нужно ограничивать группы сегментов максимального уровня вложения, в которых возникает данная проблема.
Пример 2 -
|
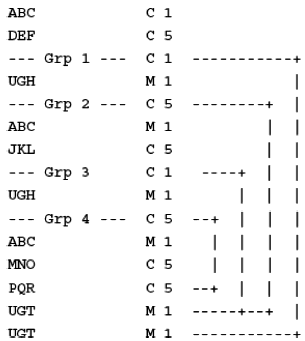
В конкретном сообщении последовательность данных могла бы выглядеть так:
ABC+...'DEF+...'UGH+1'ABC+...'JKL+...'UGH+3'ABC+...'MNO+...'PQR+...'ABC+...'UGT+3'UGT+1'.
Ее представление в виде таблицы приведено ниже.
Значение в последовательности данных | Описание |
ABC+...'DEF+...' | Автономные сегменты |
UGH+1' | Начало группы Grp 1, сигнализирующее о начале группы Grp 2 |
ABC+...'JKL+...' | Группа Grp 2 |
UGH+3' | Начало группы Grp 3, сигнализирующее о начале группы Grp 4 |
ABC+...'MNO+...'PQR+...' | Группа Grp 4 |
ABC+...' | Группа Grp 4 |
UGT+3' | Завершение группы Grp 3, сигнализирующее о завершении группы Grp 4 |
UGT+1' | Завершение группы Grp 1, сигнализирующее о завершении группы Grp 2 |
Из рассмотренного примера и таблицы видно, что АВС после JKL есть начало группы Grp 4, а АВС после PQR - это второе вхождение группы Grp 4, так как после PQR не было сегмента UGT.
Далее рассмотрим конкретную последовательность данных, представленную более детально:
ABC+...'DEF+...'UGH+1'ABC+...'JKL+...'UGH+3'ABC+...'MNO+...'PQR+...'UGT+3'ABC+...'JKL+...'.
UGH+3'ABC+...'MNO+...'PQR+...'ABC+...'MNO+...'PQR+...'ABC+...'MNO+...'PQR+...'UGT+3'UGT+1'.
Соответствующая таблица имеет вид:
Значение в последовательности данных | Описание |
ABC+...'DEF+...' | Автономные сегменты |
UGH+1' | Начало группы Grp 1, сигнализирующее о начале группы Grp2 |
ABC+...'JKL+...' | Группа Grp2 |
UGH+3' | Начало группы Grp3, сигнализирующее о начале группы Grp4 |
ABC+...'MNO+...'PQR+...' | Группа Group4 |
UGT+3' | Завершение группы Grp3, сигнализирующее о завершении группы Grp4 |
ABC+...'JKL+...' | Группа Grp2 |
UGH+3' | Начало группы Grp3, сигнализирующее о начале группы Grp4 |
ABC+...'MNO+.. 'PQR+...' | Группа Grp4 |
ABC+...'MNO+...'PQR+...' | Группа Grp4 |
ABC+...'MNO+...'PQR+...' | Группа Grp4 |
UGT+3' | Завершение группы Grp3, сигнализирующее о завершении группы Grp4 |
UGT+1' | Завершение группы Grp1, сигнализирующее о завершении группы Grp2 |
В приведенном выше примере группа Grp2 встретилась два раза. В первом случае группа Grp 4 вошла в нее один раз, а во втором - трижды.
Приложение D
(справочное)
Идентификация редакции синтаксиса
Структура составного элемента данных S001 определяется следующим образом:
|

POS - позиция компонентного элемента данных, TAG - тег, Name - наименование поля, Repr. - представление.
Компонентный элемент данных 0076 позволяет различать редакции одной версии синтаксиса. Например, внесение технической поправки в синтаксис должно сопровождаться увеличением номера редакции (начинающегося с 00) на единицу (т.е. 01, 02, и т.д.).
Справочник списков служебных кодов, который ведет UN/CEFACT, дважды в год обновляется, и каждое обновление публикуется на веб-сайте JSWG. При этом номер (последние две цифры) версии каталога списков служебных кодов (элемент данных 0080) увеличивается на единицу. Изменения номера версии синтаксиса (элемент 0002) или номера редакции синтаксиса (элемент 0076) также должны сопровождаться изменением первой или второй и третьей цифр номера версии каталога списков служебных кодов (элемент 0080), соответственно.
На рисунке D.1 показана данная система нумерации. Как видно из рисунка, в элемент 0080 входит результирующее пятиразрядное поле идентификации.
0002 | 0076 | 0080 |
4 | 00 | 40000 |
00 | 40001 | |
00 | 40002 | |
00 | 40003 | |
01 | 40100 | |
01 | 40101 | |
01 | 40102 | |
02 | 40200 | |
02 | 40201 | |
02 | 40202 | |
.. | .. | |
99 | 49900 |
Рисунок D.1 - Схема идентификации для версии синтаксиса 4
Увеличение номера версии синтаксиса (компонентный элемент данных 0002) возможно по истечении заданного числа лет при необходимости существенных изменений или усовершенствований.
На рисунке D.2 показан результат изменений в схеме идентификации после перехода к номеру версии синтаксиса 5.
0002 | 0076 | 0080 |
5 | 00 | 50000 |
00 | 50001 | |
00 | 50002 | |
01 | 50100 | |
01 | 50101 | |
01 | 50102 | |
01 | 50103 | |
02 | 50200 | |
02 | 50201 | |
02 | 50202 | |
.. | .. | |
99 | 59900 |
Рисунок D.2 - Схема идентификации для версии синтаксиса 5
Важно понимание того, что номер версии синтаксиса меняется реже остальных и в поле номера редакции синтаксиса отражаются промежуточные изменения до принятия решения относительно обновления номера версии синтаксиса. В то же время номер версии справочника списков служебных кодов меняется чаще остальных номеров, так как ежегодно выходит одна или две электронные публикации справочников списков служебных кодов.
Ниже приведен пример, как были бы назначены элементы данных составного элемента данных S001, если бы при изменении версии синтаксиса 4 добавился бы новый справочник списков служебных кодов:
|

В сегменте UNB данный элемент был бы передан в виде:
UNB+UNOA:4:40001 +......,
где UNOA = а3 - название Агентства по регулированию, состоящее из прописных букв (например, UNO = UN/ECE) и а1
- уровень заявления (например, А);
_______________
Первые три алфавитные знака.
Последний алфавитный знак.
4 = версия 4 ИСО 9735;
40001 = 4 обозначает версию синтаксиса, 00 - указывает на то, что редакция не изменилась, а 01 - каталог списков служебных кодов был изменен.
Последующее первое изменение номера редакции синтаксиса привело бы к следующим изменениям структуры составного элемента данных S001:
|

В сегменте UNB данный элемент был бы передан в виде:
UNB+UNOA:4:40101::01+......
Приложение ДА
(справочное)
Сведения о соответствии ссылочных международных стандартов ссылочным национальным стандартам
Таблица ДА.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование соответствующего национального стандарта |
ISO/IEC 646:1991 | - | * |
ISO/IEC 2022:1994 | - | * |
ISO/IEC 2382-1:1993 | - | * |
ISO/IEC 2382-4:1999 | - | * |
ИСО 6093:1985 | - | * |
ISO/IEC 6429:1992 | - | * |
ISO/IEC 6523-1:1998 | - | * |
ISO 7498-2:1989 | IDT | ГОСТ Р ИСО 7498-2-99 "Информационная технология. Взаимосвязь открытых систем. Базовая эталонная модель. Часть 2. Архитектура защиты информации" |
ISO/IEC 9594-8:1998 | IDT | ГОСТ Р ИСО/МЭК 9594-8-98 "Информационная технология. Взаимосвязь открытых систем. Справочник. Часть 8. Основы аутентификации" |
ISO 9735-2:2002 | IDT | ГОСТ Р ИСО 9735-2-2012 "Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 2. Синтаксические правила, специфичные для пакетного ЭОД" |
ISO 9735-3:2002 | IDT | ГОСТ Р ИСО 9735-3-2012 "Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 1). Часть 3. Синтаксические правила, специфичные для интерактивного ЭОД" |
ISO 9735-10:2002 | IDT | ГОСТ Р ИСО 9735-10-2016 "Электронный обмен данными в управлении, торговле и на транспорте (EDIFACT). Синтаксические правила для прикладного уровня (версия 4, редакция 2). Часть 10. Каталоги синтаксической службы"" |
ISO/IEC 10646-1:2000 | - | * |
ISO/IEC 11770-1:1996 | - | * |
ITU-T Recommendation F.400/X.400:1999 | - | * |
* Соответствующий национальный стандарт отсутствует. До его принятия рекомендуется использовать перевод на русский язык данного международного стандарта. Примечание - В настоящей таблице использовано следующее условное обозначение степени соответствия стандартов: - IDT - идентичные стандарты. | ||
УДК658.6/.9:002.006.354 | ОКС 35.240.60 |
Ключевые слова: электронный обмен данными, синтаксические правила, EDIFACT | |
Электронный текст документа
и сверен по:
, 2019
