
ГОСТ 28270-89
(ИСО 8211-85)
Группа П85
МЕЖГОСУДАРСТВЕННЫЙ СТАНДАРТ
Системы обработки информации
СПЕЦИФИКАЦИЯ ФАЙЛА ОПИСАНИЯ ДАННЫХ ДЛЯ ОБМЕНА ИНФОРМАЦИЕЙ
Information processing systems. Specification for a data descriptive file
for information interchange
MКC 35.020
ОКСТУ 4097
Дата введения 1990-07-01
ИНФОРМАЦИОННЫЕ ДАННЫЕ
1. РАЗРАБОТЧИКИ
М.М.Ефимова; А.А.Мкртумян; О.А.Антошкова; Ю.А.Васильев; Н.А.Чельцова; В.И.Федосимов
2. Постановлением Государственного комитета СССР по стандартам от 27.09.89 N 2942 стандарт Совета Экономической Взаимопомощи СТ СЭВ 6366-88 "Системы обработки информации. Спецификация файла описания данных для обмена информацией", в качестве которого непосредственно применен международный стандарт ИСО 8211-85, введен в действие непосредственно в качестве государственного стандарта СССР с 01.07.90
3. ССЫЛОЧНЫЕ НОРМАТИВНО-ТЕХНИЧЕСКИЕ ДОКУМЕНТЫ
Раздел, подраздел, пункт, | Обозначение международного стандарта | Обозначение соответствующего отечественного нормативно- |
0; 3; 4.1; 4.19; 4.35; 5.2.1.9; 6.2.1; 7.1; приложения А; В | ИСО 646 | |
1; 3; | ИСО 1001 | |
3; 4.18; 5.2.1.4; 7.1; приложения А; В | ИСО 2022 | |
1; 3 | ИСО 4341 | |
1; 3 | ИСО 6093 | - |
1; 3 | ИСО 7665 |
4. ПЕРЕИЗДАНИЕ. Январь 2006 г.
Настоящий стандарт устанавливает независимые от носителя и системы обобщенную структуру файла и форматы записей данных для обмена между системами обработки информации.
Стандарт определяет средства формального описания данных различной структуры и типа независимо от их содержания.
В целях обеспечения международного обмена информацией в качестве государственного стандарта "Системы обработки информации. Спецификация файла описания данных для обмена информацией" принят стандарт ИСО 8211 методом прямого применения с учетом опечаток и неточностей, приведенных в приложении 1 (в аутентичном тексте стандарта помечены знаком "*").
СПЕЦИФИКАЦИЯ ФАЙЛА ОПИСАНИЯ ДАННЫХ ДЛЯ ОБМЕНА ИНФОРМАЦИЕЙ
В качестве описания спецификации файла описания данных для обмена информацией следует использовать международный стандарт ИСО 8211.
АУТЕНТИЧНЫЙ ТЕКСТ МЕЖДУНАРОДНОГО СТАНДАРТА
0. ВВЕДЕНИЕ
Настоящий стандарт разработан в ответ на определенную потребность в механизме, позволяющем свободно перемещать структуры данных из одной вычислительной системы в другую, независимо от способа формирования. Структуры данных, предназначенных для обмена, могут существенно меняться как по сложности, так и по размеру, а метод осуществления обмена такими данными должен быть общий. Также желательно, чтобы любой носитель данных, такой как линия связи, магнитная лента, пакет дисков, гибкий диск и т.д., можно было использовать для физического обмена и, по возможности, вся информация, необходимая для преобразования структуры в конечной системе, содержалась в рамках информации, передаваемой на носителе данных.
Для удовлетворения этих потребностей настоящий стандарт устанавливает независимые от носителя и независимые от системы структуру файла и форматы записей данных для обмена информацией между вычислительными системами. Стандарт подразумевает использование как физических носителей данных, так и линий связи. Данные пользователя могут быть представлены любым признанным в международном масштабе набором кодированных символов и переданы в прозрачной форме. Промежуточная структура, через которую проходит информация, предназначена только для обмена и не используется в общей обработке.
Целью разработки настоящего стандарта было определение формата обмена, в который преобразовывается информация отправителя и передается в систему получателя. При получении информации в формате обмена она затем преобразовывается в формат получателя без потери структуры и содержания. Стандарт определяет метод для описания четкой структуры обмена, позволяющей принять большинство структур данных пользователя. Этот метод дает возможность отправителю сохранить структуру информации и передать ее с данными получателю таким образом, что получатель может повторно преобразовать структуру и данные в локальной системе.
С помощью настоящего стандарта могут быть описаны и обменены большинство структур данных общего использования: элементарные данные, векторы, массивы и иерархии. Такие структуры файла пользователя, как последовательная, иерархическая, реляционная и индексная, могут быть преобразованы в структуру обмена. При обмене сетевыми структурами необходима дополнительная препроцессорная и постпроцессорная обработка для сохранения логических связей.
Положения настоящего стандарта не зависят от носителей данных и требуют среды, в которой стандартные метки и структуры файлов могут быть записаны или считаны с выбранных стандартных носителей. Допускается, что записи переменной длины могут быть обработаны посредством обеспечения системы обработки файла и меток. Для преобразования файла пользователя и системы управления базой данных в файл обмена необходим вычислительный процесс. Функция преобразования должна обеспечить необходимые преобразования структуры и данных. Параметры, необходимые для определения выбора и преобразования этих элементов данных и структур в форматы, установленные настоящим стандартом, находятся вне сферы рассмотрения стандарта.
В управляющих полях файла обмена необходимо использовать набор кодированных символов по стандарту ИСО 646 (международная справочная версия по ГОСТ 27463), в полях данных пользователя допускается применять расширенные наборы символов.
Настоящий стандарт предусматривает три уровня обмена, из которых пользователь может выбирать необходимый ему, исходя из сложности структур данных.
Первый уровень поддерживает множество полей, содержащих простые, неструктурированные строки символов.
Второй уровень поддерживает первый уровень и обрабатывает множество полей, содержащих структурированные данные пользователя, охватывающие все разнообразие типов данных.
Третий уровень поддерживает второй уровень и иерархические структуры данных.
Примечание. Дополнительная информация по применению настоящего стандарта приведена в приложении А.
1. НАЗНАЧЕНИЕ И ОБЛАСТЬ ПРИМЕНЕНИЯ
Настоящий стандарт устанавливает формат обмена для облегчения передачи файлов, содержащих записи данных, между вычислительными системами. Стандарт не предназначен для использования внутри локальных систем. Стандарт определяет обобщенную структуру файла, которую можно использовать для передачи между системами записей, содержащих широкое разнообразие структур и типов данных. Стандарт представляет лишь средство описания содержимого записей данных, но не определяет самого содержимого записи.
Стандарт устанавливает:
1) независимые от носителя данных файл и описания записей данных для обмена информацией. Он также предполагает использование других международных стандартов по структуре и разметке файлов, таких, как ИСО 1001 (ГОСТ 25752), ИСО 4341 (ГОСТ 28104), ИСО 7665 (ГОСТ 28081);
2) описание элементов данных: векторов, массивов и иерархий, содержащих строки символов, строки битов и числовые формы.
Числовые формы определены в ИСО 6093;
3) файл описания данных, включающий в себя запись описания данных и сопутствующие ей записи данных, которые позволяют обмениваться информацией с минимальным специфичным внешним описанием;
4) запись описания данных, которая характеризует поле данных в пределах сопутствующих записей данных;
5) три уровня обмена в зависимости от сложности допустимой структуры данных (по п.5.2.1.2).
2. СООТВЕТСТВИЕ
Файл обмена соответствует требованиям настоящего стандарта, если все записи описания данных и записи данных соответствуют спецификациям, определенным в стандарте. В формулировке соответствия следует указывать уровень обмена, которому соответствует содержимое файла.
Настоящий стандарт не устанавливает требования к обработке и реализации, поэтому сама эта обработка не может ему соответствовать.
3. ССЫЛКИ
ИСО 646 Обработка информации. 7-битный кодированный набор символов ИСО для обмена информацией.
ИСО 1001 Обработка информации. Структура и разметка файла на магнитной ленте для обмена информацией.
ИСО 2022 Обработка информации. 7- и 8-битные кодированные наборы символов ИСО. Методы расширения кода.
ИСО 4341 Обработка информации. Структура и разметка файла на кассетах и катушках с магнитной лентой для обмена информацией.
ИСО 6093 Обработка информации. Представление числовых значений в строках символов для обмена информацией.
ИСО 7665 Обработка информации. Структура и разметка файла на гибком магнитном диске для обмена информацией.
Международный регистр ИСО наборов символов, используемых с расширенными последовательностями, также связан с настоящим стандартом.
4. ТЕРМИНЫ И ОПРЕДЕЛЕНИЯ
В настоящем стандарте применяются следующие термины и определения*
__________________
* Алфавитный указатель терминов на русском языке и их эквиваленты на английском языке приведены в приложении 2.
4.1. Буквенно-цифровой символ: символ, встречающийся в колонках 2-7 включительно (кроме позиции 7/15) международной ссылочной версии ИСО 646 (ГОСТ 27463).
Примечание. Символы, определенные в настоящем стандарте, представлены их позицией (колонка/ряд) в таблице кодированного набора символов по ИСО 646 (ГОСТ 27463) или их акронимами (обозначениями по ГОСТ 27465), например, АР2, РЗ, РЭ.
4.2. Описатель массива: последовательность чисел, определяющая размерность и величину массива.
4.3. Базовый адрес данных: элемент данных, значение которого равно числу байтов, предшествующих первому полю данных, равен суммарной длине ведущей метки и справочника, включая разделитель поля в конце справочника. Началом отсчета (0) является первый байт ведущей метки.
4.4. Поле битов: поле данных, содержащее только двоичные цифры и, при необходимости, выравниваемое влево двоичными нулями до границы байта (см. также термин "строка битов в символьном режиме").
4.5. Байт: набор n битов.
Примечание. Положения настоящего стандарта не зависят от носителя (среды), а число битов зависит от носителя.
4.6. Декартова метка: массив идентификаторов, образованный декартовым произведением элементов двух (или более) векторных меток. Элементы массива имеют тот же порядок, что и элементы прямого произведения, так что, если и
- векторные метки
= [а(1),..., а (n)] и
= [b(l), . . . , b (m)], то декартова метка
·
= [а(1) b(1), а(1) b(2),..., а(1) b(m),..., a(n) b(m)], где a(i) b(j) - соединение a(i) и b(j), которое образует идентификатор элемента i, j соответствующего массива данных.
4.7. Строка битов в символьном режиме: последовательность символов (0 или 1), представляющая строку двоичных цифр (см. также термин "поле битов").
4.8. Составное поле данных: поле, содержащее один или несколько неделимых элементов данных.
4.9. Файл описания данных (ФОД): файл, содержащий запись описания данных и относящиеся к ней записи данных.
4.10. Запись описания данных (ЗОД): запись, логически предшествующая записям данных и содержащая управляющие параметры и определения данных, необходимые для интерпретации относящихся к ней записей данных. Запись описания данных - это первая логическая запись файла, кроме меток файла (если таковые имеются).
4.11. Запись данных (ЗД): логическая запись, содержащая данные, являющиеся объектом обмена (данные пользователя).
4.12. Структура с разделителями: структура, образованная набором элементов данных, ограниченных разделителями.
4.13. Разделитель: единичный символ, разделяющий элементы данных и поля данных (использование разделителей по табл.1).
4.14. Справочник: таблица меток полей и ссылок на соответствующие поля данных.
4.15. Статья справочника: поле фиксированной длины в справочнике, содержащее информацию о конкретном поле в записи: метке поля, длине и местоположения поля.
4.16. Элементарный: неделимый без потери смыслового значения.
4.17. План статьи: поле в ведущей метке, используемое для указания структуры статей справочника.
4.18. Управляющий символ АР 2: символ, обеспечивающий возможность использования дополнительных символов. Меняет значение ограниченного набора следующих непосредственно за ним комбинаций битов. Использование этого символа определено в ИСО 2022 (ГОСТ 27466).
4.19. Разделитель поля (РЗ): символ, используемый для ограничения поля записи, (1/14) по ИСО 646 (ГОСТ 27463, управляющий символ РАЗДЕЛИТЕЛЬ ЗАПИСЕЙ по ГОСТ 27465).
4.20. Файл: совокупность связанных записей, рассматриваемая как целое.
4.21. Заголовок файла: строка символов, которая дает воспроизводимое описательное заглавие для файла обмена. Заголовок может не совпадать с именем файла.
4.22. Иерархия, иерархическая структура: корневая, упорядоченная древовидная структура, содержащая высший корневой узел с последовательным множеством упорядоченных поддеревьев, расположенных в узлах нисходящих уровней, и заканчивающаяся узлами-листьями.
4.23. Уровень обмена, уровень: обозначение предписанного поднабора требований данного международного стандарта.
4.24. Формат обмена: формат для обмена записями, в отличие от локальной обработки.
4.25. Метка: строка символов, используемая для идентификации либо наименования поля или подполя и их содержимого.
4.26. Ведущая метка: поле фиксированной длины, присутствующее в начале каждой записи и обеспечивающее параметры для обработки записи.
4.27. Местоположение: число байтов до позиции первого байта поля.
Местоположение в ведущей метке и справочнике указывается относительно первого (0) байта ведущей метки, а местоположение полей описания данных и полей данных - относительно базового адреса данных.
4.28. Логическая запись, запись: совокупность взаимосвязанных элементов данных, не зависящая от их представления на носителе.
4.29. Отображать: устанавливать соответствие между элементами двух структур.
4.30. Пустой: означает условие "неприсутствия" логического объекта, обычно элемента данных, строки или набора.
4.31. Последовательность прямого обхода: последовательность узлов иерархии, создаваемая следующим рекурсивным алгоритмом:
1) войти в корневой узел дерева;
2) просмотреть крайнее слева поддерево, которое предварительно не просматривалось;
3) если 2) невозможно, то возвратиться к узлу, высшему по отношению к поддереву, и перейти к 2).
4.32. Длина записи: элемент данных, значение которого равно длине записи в байтах.
4.33. Относительная позиция (ОП): позиция байта, выраженная целым десятичным числом относительно начала поля.
Первая относительная позиция нумеруется "0".
4.34. Метка поля: идентификатор в статье справочника, используемый для определения внутреннего имени соответствующего поля.
4.35. Разделитель элементов (РЭ): символ, используемый для ограничения некоторых типов подполей, внутри полей переменной длины как в ЗОД, так и в ЗД (1/15) по ИСО 646 (ГОСТ 27463, управляющий символ РАЗДЕЛИТЕЛЬ ЭЛЕМЕНТОВ по ГОСТ 27465).
4.36. Поле переменной длины: поле, длина которого меняется при различных случаях употребления.
4.37. Векторная метка: вектор, элементами которого являются метки (т.е. идентификаторы "столбца" или "строки"), используемые для идентификации каждого элемента в векторе элементов данных.
5. ФАЙЛ ОБМЕНА
5.1. Общая структура
Настоящий пункт определяет общую структуру файла. Последующие пункты дают детальные спецификации. Схематичное представление файла и меток файла приведено на черт.1.
Схематичное представление файла и меток файла
Стандартные начальные метки файла | |
Файл описания данных (ФОД) | Запись описания данных (ЗОД) |
Запись данных (ЗД) | |
Стандартные конечные метки файла | |
Черт.1
Настоящий стандарт определяет множество файлов описания данных (ФОД), каждый из которых содержит логические записи с метками, требуемыми ИСО для файла обмена, или заготовками для конкретного носителя. Каждый файл состоит из следующих логических записей:
1) записи описания данных (ЗОД);
2) записей данных (ЗД).
Общая структура приведена на черт.2, который дает расширенное логическое представление ЗОД и ЗД, ведущих меток и справочников каждой записи, типичных записей и полей типичных данных для каждой записи. Записи ЗОД и ЗД имеют одинаковые структуры ведущей метки, справочника, записи и поля, хотя их содержимое будет различно. При обмене повторяющимися данными с фиксированным форматом допускается опускать повторение идентичных ведущих меток и справочников ЗД.
Примечания:
1. На черт.2 приведены логическая последовательность расположения полей и значение некоторых длин полей. Последовательность полей представлена для физически последовательного носителя.
2. Специальные метки поля в данном стандарте описаны в следующем формате: 0..., где
является десятичным числом, а "0 ..." означает ведущие нули слева для заполнения поля метки.
Общая логическая структура ФОД
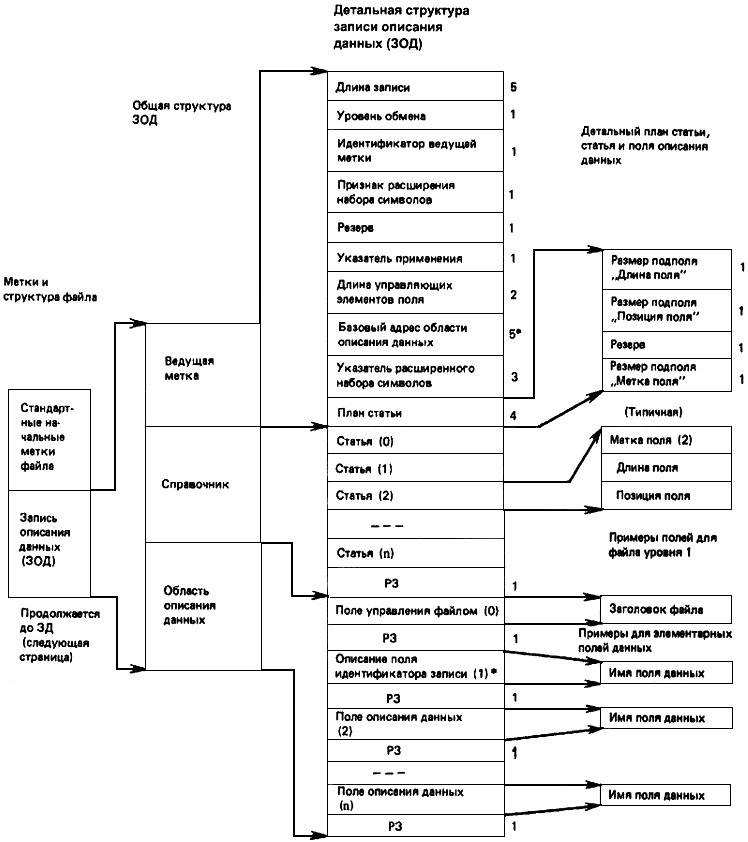
Примечания:
1. РЗ - разделитель поля, управляющий символ разделения информации (РЗ).
2. Размеры полей фиксированной длины указаны в байтах, справа от каждого поля.
3. Метки полей и соответствующие им статьи и поля обозначены цифрами в скобках для каждого поля.
Примеры полей описания данных для файлов уровня 3*, содержащих составные поля данных, приведены на черт.12.
Черт.2, лист 1
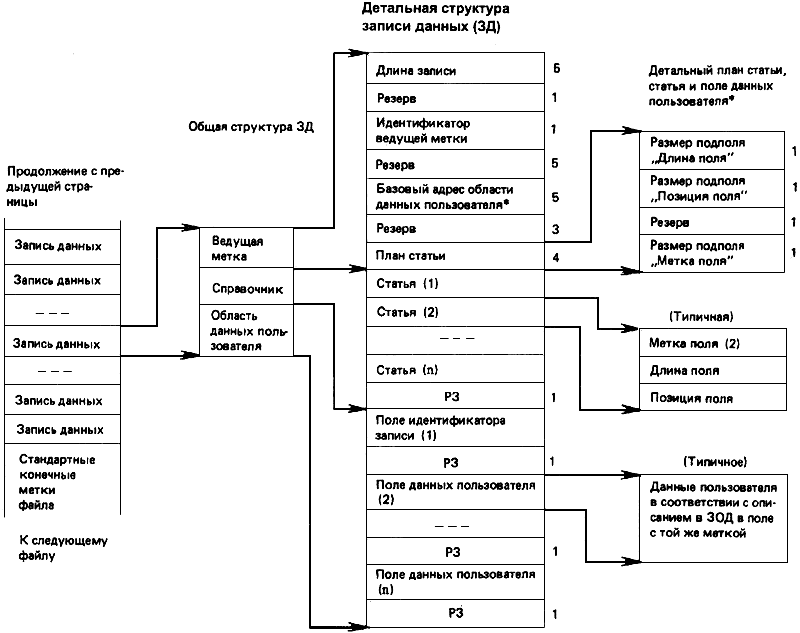
Черт.2, лист 2
Каждое поле описания данных ЗОД содержит описание данных, представленных в поле данных ЗД, с той же меткой поля. ЗОД (но не ЗД) имеет специальную метку поля 0...0 и соответствующее поле, которое содержит управляющие элементы поля, необязательный заголовок файла и в случае иерархии - информацию о структуре. Каждая ЗД имеет специальное поле для идентификации записи, а ЗОД содержит описание этого поля в поле описания данных с той же меткой поля (0...1). Содержимое полей переменной длины ЗОД изменяется в зависимости от значений параметров в ведущей метке.
Поля описания данных ЗОД, приведенные на черт.2, даны для элементарных символьных полей данных, а те, что показаны на черт.12, - для составных полей данных, включая все дополнительные подполя.
Примечания:
1. Содержимое поля данных ЗД может существенно меняться в зависимости от его описания в ЗОД, поэтому на черт.2 и 12 примеры отсутствуют. Примеры приведены в приложении В.
2. Далее по тексту стандарта длина послей, кроме полей битов, указана в байтах, длина которых в битах может зависеть от носителя.
Содержимое полей рассматривается как символы; в полях данных пользователя допускаются наборы многобайтовых символов (по п.7.5*), в таких случаях длина поля не равна числу символов.
5.2. Запись описания данных (ЗОД)
ЗОД является первой записью файла и состоит из областей и разделителей, приведенных на черт.3.
Структура ЗОД
Имя области | Длина |
Ведущая метка | 24 |
Справочник | k |
Разделитель поля | 1 |
Область описания данных | Переменная |
Разделитель поля | 1 |
Черт.3
Каждая ЗОД состоит из:
1) ведущей метки длиной 24 символа;
2) справочника длиной kр, ограниченного разделителем поля (1/14),
где k - число статей справочника и р - длина каждой статьи (по п.5.2.2);
3) набора полей переменной длины, каждое из которых заканчивается разделителем поля (1/14).
5.2.1. Ведущая метка ЗОД
Состоит из полей, приведенных на черт.4 и определяемых далее в пп.5.2.1.1-5.2.1.9.
Структура ведущей метки ЗОД
ОП | Имя поля | Длина | Содержимое |
0 | Длина записи | 5 | Цифры |
5 | Уровень обмена | 1 | Цифры |
6 | Идентификатор ведущей метки | 1 | Символ |
7 | Признак расширения набора символов | 1 | Символ |
8 | Резерв | 1 | Символ ПРОБЕЛ |
9 | Указатель применения | 1 | Символ |
10 | Длина управляющих элементов поля | 2 | Цифры |
12 | Базовый адрес области описания данных* | 5 | Цифры |
17 | Указатель расширенного набора символов* | 3 | Символы |
20 | План статьи | 4 | Цифры |
Черт.4
5.2.1.1. Поле "Длина записи" (ЗОД ОП 0-4)
Определяет общую длину ЗОД в байтах. Содержимое этого поля должно быть цифровым. Значение "0" в этом поле означает длину ЗОД, превышающую 99999.
5.2.1.2. Поле "Уровень обмена" (ЗОД ОП 5)
Должно определять уровень обмена (по разд.0*). Содержимым этого поля должны быть цифры 1, 2 или 3:
1 - означает, что файл соответствует уровню обмена 1;
2 - означает, что файл соответствует уровню обмена 2;
3 - означает, что файл соответствует уровню обмена 3.
Файл уровня 1 должен содержать элементарные символьные поля данных (по п.6.1), но не составные поля данных и не иерархические структуры. Файл уровня 2 должен содержать составные поля данных (по п.6.2), но не иерархические структуры. Файл уровня 3 должен содержать составные поля данных и список пар меток полей (по 5.2.3.1.3*), описывающих иерархические структуры.
5.2.1.3. Поле "Идентификатор ведущей метки" (ЗОД ОП 6)
Указывает, что запись является ЗОД и содержит символ L (прописная латинская буква L).
5.2.1.4. Поле "Признак расширения набора символов" (ЗОД ОП 7)
Определяет использование в полях данных последовательности АР2 для обозначения расширенных наборов символов, как определено в ИСО 2022 (ГОСТ 27466).
Символы в этом поле означают:
ПРОБЕЛ - расширение не используется;
Е (прописная латинская буква Е) - расширение используется.
5.2.1.5. Резерв (ЗОД ОП 8)
Поле резервируется для последующей стандартизации.
5.2.1.6. Поле "Указатель применения" (ЗОД ОП 9)
Резервируется для последующей стандартизации. Содержит символ ПРОБЕЛ.
5.2.1.7. Поле "Длина управляющих элементов поля" (ЗОД ОП 10-11)
Определяет число байтов поля описания данных, отведенных для указания кодов типа и структуры данных, разделителей и других позиций, резервируемых для последующей стандартизации (по п.5.2.3.1.1).
Содержимым этого поля должны быть цифры 00, 03 или 09 (по пп.5.3.3.2, 7.2*).
5.2.1.8. Поле "Базовый адрес области описания данных" (ЗОД ОП 12-16)
Определяет позицию первого поля описания данных в ЗОД.
Примечание. Первым полем описания данных является поле управления файла или поле описания идентификатора записи.
Содержимое этого поля должно быть цифровым и равно суммарной длине (в байтах) ведущей метки и справочника, включая разделитель поля в конце справочника.
5.2.1.9. Поле "Указатель расширенного набора символов" (ЗОД ОП 17-19)
Указывает на использование в файле расширенных наборов символов по умолчанию.
Символы, указанные в поле, означают:
1) (2/0) (2/0) (2/0) - по умолчанию для файла принят только набор символов Международной ссылочной версии по ИСО 646 (ГОСТ 27463);
2) (2/0) (2/1) (2/0) - расширенные наборы символов приняты по умолчанию для одного или более полей данных (по п.7.2*);
3) усеченная последовательность АР2 - расширенный набор символов принят по умолчанию для файла в целом (по п.7.3*).
5.2.1.10. Поле "План статьи" (ЗОД ОП 20-23)
Определяет длины подполей статей справочника и состоит из подполей, приведенных на черт.5 (по п.5.2.2). Каждое подполе этого поля должно содержать одну цифру.
Структура плана статьи справочника ЗОД
ОП | Имя подполя | Длина | Содержимое |
20 | Размер подполя "Длина поля" | 1 | Цифра |
21 | Размер подполя "Позиция поля" | 1 | Цифра |
22 | Резерв | 1 | Цифра |
23 | Размер подполя "Метка поля" | 1 | Цифра |
Черт.5
5.2.1.10.1. Размер подполя "Длина поля" (ЗОД ОП 20)
Подполе определяет длину (в байтах) подполя статей справочника "Длина поля" и содержит цифру от 1 до 9 включительно.
5.2.1.10.2. Размер подполя "Позиция поля" (ЗОД ОП 21)
Подполе определяет длину (в байтах) подполя статей справочника "Позиция поля" и содержит цифру от 1 до 9 включительно.
5.2.1.10.3. Резерв (ЗОД ОП 22)
Подполе резервируется для последующей стандартизации как расширение плана статьи справочника и содержит цифру 0.
5.2.1.10.4. Размер подполя "Метка поля" (ЗОД ОП 23)
Подполе определяет длину (в байтах) подполя статей справочника "Метка поля" и содержит цифру от 1 до 7 включительно.
Примечание. В п.5.2 используются следующие обозначения:
m - размер подполя "Длина поля";
n - размер подполя "Позиция поля";
t - размер подполя "Метка поля".
5.2.2. Справочник ЗОД
Справочник ЗОД состоит из ряда статей, длины подполей которых должны быть указаны в поле "План статьи". Справочник ЗОД содержит одну статью для каждого поля описания данных и заканчивается разделителем поля (1/14). ЗОД определяет все метки полей ЗД.
Статья справочника ЗОД определяет местоположение и длину соответствующего поля описания данных и состоит из подписей, приведенных на черт.6. Каждая статья содержит метку поля, длину поля и позицию поля в указанной последовательности и состоит из (m+n+t) байтов.
Структура статьи справочника
ОП | Имя подполя | Длина | Содержимое |
р (i-1) | Метка поля | t | Буквенно-цифровое |
р (i-1)+t | Длина поля | m | Цифры |
р (i-1)+t+m | Позиция поля | n | Цифры |
где р=t+m+n;
i=индекс статьи справочника (i=1...n).
Черт.6
Статьи справочника ЗОД должны однозначно соответствовать полям описания данных. Для иерархических структур данных (по п.5.2.3.1.3) последовательность статей справочника ЗОД должна соответствовать последовательности прямого обхода структуры типа "дерево".
5.2.2.1. Подполе "Метка поля " ЗОД
Содержит метку поля, которая идентифицирует поле описания данных и может содержать от одного до семи буквенно цифровых символов. Одна и та же метка поля должна встречаться в пределах ЗОД только один раз.
5.2.2.1.1. Метка поля "0...0" идентифицирует необязательное поле управления файла и, если присутствует, может встречаться только в ЗОД.
5.2.2.1.2. Метка поля "0...1" должна присутствовать в каждой записи только один раз и идентифицировать поле идентификатора записи.
5.2.2.1.3. Метка поля "0...2", если таковая используется, должна идентифицировать необязательное поле пользователя в ЗОД, которое не имеет соответствующего поля данных в ЗД. Реализация должна передавать это поле пользователю для обработки.
Примечание. Содержимое этого поля определяется пользователем и может быть использовано для передачи любого дополнительного описания файла (например, атрибуты файла, связанные с обменом) или вспомогательных средств управления обработкой файла, или информации о применении.
5.2.2.1.4. Метки поля с "0...3" по "0...9" зарезервированы для последующей стандартизации.
5.2.2.1.5. Метки поля с "0...0" по "0...9" включительно, если таковые имеются, должны использоваться в начале справочника ЗОД в порядке возрастания их числового значения.
5.2.2.2. Подполе "Длина поля" ЗОД
Определяет длину поля (в байтах), которому оно соответствует, и содержит выровненное вправо целое число, дополненное ведущими нулями. Длина поля включает разделитель поля.
5.2.2.3. Подполе "Позиция поля" ЗОД
Определяет относительную позицию первого байта в поле, к которому относится статья справочника и содержит выровненное вправо целое число, дополненное ведущими нулями. Это число (по величине) должно быть определено относительно базового адреса области описания данных, указанного в ЗОД (ОП 12-16). Первый байт первого поля, следующего за справочником, должен иметь номер "0".
5.2.3. Область описания данных
Содержит в своих полях такую информацию, которая определяет и описывает соответствующие (имеющие ту же метку) поля данных ЗД и обеспечивает управляющие параметры для автоматизированной обработки. Эти поля должны иметь определенный формат, установленный содержимым ведущей метки ЗОД. Все поля должны заканчиваться разделителем поля (1/14).
5.2.3.1. Поле управления файлом (метка поля 0...0)
Содержит следующие подполя (черт.7):
1) управляющие элементы поля (если таковые имеются);
2) необязательный заголовок файла;
3) список упорядоченных пар меток полей (только для иерархических записей).
Структура поля управления файлом
Управляющие элементы поля | Заголовок файла | РЭ | Список пар меток полей | РЗ |
Черт.7
Поле должно заканчиваться разделителем поля (1/14).
5.2.3.1.1. Подполе "Управляющие элементы поля"
Подполе присутствует только в файлах уровня 2 и 3, и его длина определяется содержимым поля "Длина управляющих элементов поля" ЗОД ОП 10-11 (по п.5.2.1.7). Эти управляющие элементы не должны использоваться в поле управления файлом* и должны иметь значения "0" или "ПРОБЕЛ" (по п.6.2.2).
5.2.3.1.2. Подполе "Заголовок файла"
Определяет необязательный заголовок файла, следующий за управляющими элементами поля, и содержит строку символов, являющуюся внешним именем файла обмена.
5.2.3.1.3. Список пар меток полей
Описывает иерархическую структуру. Он следует за подполем заголовка файла и отделен от него разделителем элементов (1/15). Попарное соединение меток полей определяется структурным порядком от корневого узла дерева до узла-листа в общей структуре данных. Эти пары могут быть размещены в списке в любой последовательности и должны быть смежными. Метка корня должна быть меткой поля идентификатора записи (0...1). Метки полей с 0...2 по 0...9 включительно не должны использоваться в описании структуры.
Примечание. Переменные иерархические структуры данных, допускаемые в ЗД, описываются посредством последовательностей прямого обхода дерева данных и списка пар меток полей, выражающих логическую связь "старший/подчиненный" между узлами дерева данных. Структуры данных в ЗД должны образовываться из общего дерева данных путем повторения или исключения узлов и поддеревьев. Последовательность прямого обхода общего дерева данных обеспечивается порядком статей справочника ЗОД (по п.5.2.2). Последовательность прямого обхода для каждого полученного дерева данных в ЗД определяется последовательностью статей справочника ЗД (по п.5.3.2). Дальнейшее пояснение упорядоченных пар меток полей приведено в приложении С.
5.2.3.2. Описание поля идентификатора записи (метка поля 0...1)
Область описания данных содержит поле описания данных, которое описывает поле идентификатора записи ЗД. Это поле описания данных должно соответствовать требованиям к полям описания, характеризующим поля данных пользователя согласно п.5.3.3 и разд.6.
5.2.3.3. Описания полей данных пользователя
Область описания данных содержит после описания данных для каждого из полей данных пользователя. Поля описания данных определены в разд.6.
5.3. Запись данных (ЗД)
Записи данных должны состоять из областей и разделителей, приведенных на черт.8
Структура ЗД*
Имя области | Длина |
Ведущая метка | 24 |
Справочник | k' |
Разделитель поля | 1 |
Область данных пользователя | Переменная |
Разделитель поля | 1 |
где k' - число статей в справочнике;
р' - число байтов в статье справочника ЗД.
Черт.8
Если в файле обмена за записями переменной длины следуют записи фиксированной длины (т.е. записи содержат только поля данных фиксированной длины), где все ЗД, начиная с некоторой, имеют идентичные значения ведущей метки и справочника, то ведущую метку и справочник первой ЗД, имеющей ведущую метку и справочник, идентичные остальным ЗД, применяют ко всем последующим ЗД. В этом случае в последующих ЗД ведущая метка и справочник могут быть опущены.
5.3.1. Ведущая метка ЗД
Ведущая метка каждой ЗД должна состоять из полей, приведенных на черт.9, и определенных далее в пп.5.3.1.1-5.3.1.7.
Структура ведущей метки ЗД
ОП | Имя поля | Длина | Содержимое |
0 | Длина записи | 5 | Цифры |
5 | Резерв | 1 | Символ ПРОБЕЛ |
6 | Идентификатор ведущей метки | 1 | Символ |
7 | Резерв | 5 | Символы ПРОБЕЛ |
12 | Базовый адрес области данных пользователя* | 5 | Цифры |
17 | Резерв | 3 | Символы ПРОБЕЛ |
20 | План статьи | 4 | Цифры |
Черт.9
5.3.1.1. Поле "Длина записи" (ЗД ОП 0-4)
Определяет общую длину ЗД в байтах. Содержание поля цифровое. Значение "0" в этом поле означает длину ЗД, превышающую 99999.
5.3.1.2. Резерв (ЗД ОП 5)
Поле резервируется для последующей стандартизации
5.3.1.3. Поле "Идентификатор ведущей метки" (ЗД ОП 6)
Определяет, что запись является ЗД, и указывает на наличие ведущих меток и справочников в последующих ЗД.
Символы в этом поле означают:
прописная латинская буква D - последующая ЗД содержит метку и справочник;
прописная латинская буква R - ведущая метка и справочник в последующих ЗД (следующих за текущей ЗД) отсутствуют, и ведущую метку и справочник текущей ЗД следует применять для каждой последующей ЗД.
5.3.1.4. Резерв (ЗД ОП 7-11)
Данное поле резервируется для последующей стандартизации.
5.3.1.5. Базовый адрес области данных (ЗД ОП 12-16)
Поле определяет позицию первого поля данных пользователя в ЗД.
Примечание. Первым полем данных пользователя будет поле идентификатора записи.
5.3.1.6. Резерв (ЗД ОП 17-19)
Поле резервируется для последующей стандартизации
5.3.1.7. Поле "План статьи" (ЗД ОП 20-23)
Определяет длины подполей статей справочника внутри каждой ЗД и состоит из подполей, приведенных на черт.10. Каждое подполе этого поля должно содержать одну цифру.
Структура плана статьи ЗД
ОП | Имя подполя | Длина | Содержимое |
20 | Размер подполя "Длина поля" | 1 | Цифра |
21 | Размер подполя "Позиция поля" | 1 | Цифра |
22 | Резерв | 1 | Цифра |
23 | Размер подполя "Метка поля" | 1 | Цифра |
Черт.10
5.3.1.7.1. Размер подполя "Длина поля" (ЗД ОП 20)
Подполе определяет длину (в байтах) подполя статей справочника "Длина поля" и содержит цифру от 1 до 9 включительно.
5.3.1.7.2. Размер подполя "Позиция поля" (ЗД ОП 21)
Подполе определяет длину (в байтах) подполя статей справочника "Позиция поля" и содержит цифру от 1 до 9 включительно.
5.3.1.7.3. Резерв (ЗД ОП 22)
Подполе резервируется для последующей стандартизации в целях расширения плана статьи и содержит цифру 0.
5.3.1.7.4. Размер подполя "Метка поля" (ЗД ОП 23)
Подполе определяет длину (в байтах) подполя статей справочника "Метка поля" и содержит цифру от 1 до 7 включительно. Значение, указанное в этом подполе, должно быть равно значению, указанному в подполе "Размер подполя "Метка поля" ЗОД ОП 23.
Примечание. В п.5.3 используются следующие обозначения:
m' - размер подполя "Длина поля";
n' - размер подполя "Позиция поля";
t - размер подполя "Метка поля".
5.3.2. Справочник ЗД
Состоит из повторяющихся статей справочника ЗД, длины подполей которых определяются планом статьи. Он должен содержать одну статью справочника для каждого поля данных пользователя и должен заканчиваться разделителем поля (1/14). Все метки полей должны быть определены в ЗОД.
Статья справочника определяет местоположение и длину соответствующего поля данных пользователя и состоит из подполей, приведенных на черт.11. Каждая статья содержит метку поля, длину поля и позицию поля в указанной последовательности и состоит из m'+n'+t байтов.
Структура статьи справочника ЗД
ОП | Имя подполя | Длина | Содержимое |
p(i-1) | Метка поля | t | Буквенно-цифровое |
р(i-1)+t | Длина поля | m' | Цифры |
р (i-1)+t+m' | Позиция поля | n' | Цифры |
где р=t+m'+n';
i=индекс статьи справочника (i=1...n).
Черт.11
Статьи справочника должны однозначно соответствовать полям данных пользователя. Любая метка поля, за исключением метки поля "0...1", может повторяться в справочнике ЗД. Для неиерархических структур повторяющиеся метки полей должны быть логически смежными в справочнике, и метки полей ЗД должны встречаться в том же порядке, что и метки полей ЗОД. Метки полей, соответствующие недостающим полям данных пользователя, могут быть опущены в справочнике, если они не требуются для описания структуры. Для иерархических структур данных (по п.5.2.3.1.3) статьи справочника ЗД должны иметь тот же порядок, что и последовательность прямого обхода соответствующих полей данных полученного дерева данных этой ЗД.
5.3.2.1. Подполе "Метка поля" 3Д
Содержит метку поля, идентифицирующую поле данных, и может содержать от 1 до 7 буквенно-цифровых символов.
Метка поля "0...1" идентифицирует поле идентификатора записи, должна встречаться только один раз в каждой ЗД и должна быть в справочнике ЗД первой.
5.3.2.2. Подполе "Длина поля" ЗД
Определяет длину поля (в байтах), которому оно соответствует. Подполе содержит целое число, выровненное вправо и дополненное ведущими нулями. Длина поля включает разделитель поля.
5.3.2.3. Подполе "Позиция поля" ЗД
Определяет относительную позицию первого байта в поле, к которому относится статья. Подполе содержит целое число, выровненное вправо и дополненное ведущими нулями. Позицию поля указывают относительно базового адреса области данных пользователя*, указанного в ЗД ОП 12-16. Первый байт первого поля, следующего за справочником, должен иметь нумерацию 0.
5.3.3. Область данных пользователя
Поля данных области данных пользователя содержат информацию пользователя, предназначенную для обмена. Структура данных и тип данных для каждого поля данных определяются полем описания данных ЗОД с соответствующей меткой поля. Подполя содержат элементы данных, соответствующие меткам, приведенным в соответствующих подполях ЗОД. Каждое поле заканчивается разделителем поля (1/14). В структуре с разделителями, где символом разделения подполей является символ РЭ (1/15), пропущенные элементы данных должны быть представлены следующими один за другим разделителями. Последовательность разделителей смежных подполей может быть заменена разделителем поля (1/14).
Поля данных, содержащие элементарные символы, окончание которых определяется длиной поля, шириной формата, разделителем, определенным пользователем, или разделителем поля, могут содержать символ разделения элементов (РЭ), который будет трактоваться при реализации как символ данных пользователя.
Описание данных пользователя приведено в разд.6.
5.3.3.1. Поле идентификатора записи (метка поля 0...1)
Каждая ЗД содержит только одно поле идентификатора записи. Содержание поля идентификатора записи ЗД должно согласовываться с соответствующим полем описания данных ЗОД и должно быть уникальным в пределах файла. Идентификатор должен быть выровнен влево и дополнен справа пробелами (2/0), если он алфавитно-цифровой, или выровнен вправо и дополнен слева нулями (3,0), если он цифровой.
Примечание. Уникальные идентификаторы рассмотрены в разд.А.3 приложения А.
5.3.3.2. Поля данных пользователя
5.3.3.2.1. Элементарные символьные поля данных
Поля данных пользователя ЗД содержат строку символов, заканчивающуюся соответствующим разделителем поля (см. табл.1).
Таблица 1
Разделители и их использование
Разделитель информации | Печатный символ | Запись | Использование |
(РЗ) 1/14 | ; | ЗОД, ЗД | Разделитель поля |
(РЗ) 1/15 | & | ЗД | Разделитель элементов: |
1) для ограничения подполей в полях, где это не определяется форматом; | |||
ЗОД | 2) для ограничения до и после необязательного имени поля и векторной метки; | ||
ЗОД | 3) для начального ограничения управляющих элементов иерархической структуры в поле с меткой 0...0; | ||
ЗОД | 4) для начального ограничения управляющих элементов формата | ||
(!) 2/1 | ! | ЗОД | Для ограничения меток элементов данных в пределах векторной метки |
(*) 2/10 | * | ЗОД | Для ограничения векторных меток в декартовой метке |
________________
Графическое изображение этих разделителей по ИСО 646 (ГОСТ 27465) отсутствует в некоторых печатающих устройствах. Символы, приведенные в графе "Печатный символ", заменяют стандартное графическое представление разделителей (для удобства чтения) далее по всему тексту стандарта.
Файлы обмена, состоящие только из полей данных указанных структуры и типа, должны иметь следующие управляющие символы в своей ведущей метке ЗОД:
Поле ведущей метки | ОП | Символы |
Указатель применения | 9 | ПРОБЕЛ |
Длина управляющих элементов поля | 10 и 11 | 00 |
Остальные поля ведущей метки ЗОД определяются по п.5.2.1.
5.3.3.2.2. Составные поля данных
Данными в этих полях должны быть символы, разделители и строки битов, которые соответствуют определениям, содержащимся в соответствующем поле описания данных (по п.6.2).
Файлы обмена, состоящие исключительно из полей указанных структур, имеют следующие символы в своей ведущей метке ЗОД:
Поле ведущей метки | ОП | Символы |
Указатель применения | 9 | ПРОБЕЛ |
Длина управляющих элементов поля | 10 и 11 | 06 |
Остальные поля ведущей метки ЗОД определяются по п.5.2.1.
6. ОПИСАНИЕ ТИПОВ И СТРУКТУР ДАННЫХ ПОЛЬЗОВАТЕЛЯ
6.1. Описание элементарных символьных полей данных
Настоящий пункт определяет метод описания данных пользователя, представляющих собой строку элементарных символов.
Поле описания данных для элементарных полей данных должно содержать только строку символов, представляющую собой имя поля данных пользователя (см. черт.2).
6.2. Описание составных полей данных
Настоящий пункт определяет метод для описания структур и типов данных более сложных, чем те, которые охватывает п.6.1.
Структуры данных, определенные в этом пункте, могут быть элементарными, векторными и структурами массивов, содержащих строки символов, числа с неявной точкой, с явной точкой, масштабированные с явной точкой, строку битов символьного режима, поле битов и смешанные типы данных. Поле описания данных должно содержать управляющую информацию, разделители, имя поля, метки подполей для векторов и массивов и информацию о формате поля данных по пп.6.2.1-6.2.4 и 7.1.
6.2.1. Поля описания данных
Поля описания данных для составных полей данных должны содержать управляющие элементы поля, имя поля данных, метки элементов данных и форматы данных (примеры приведены на черт.12). Управляющие элементы поля, имена, метки, форматы допустимых структур и типов данных приведены в табл.2 и определяются далее в этом подразделе. Использование разделителей приведено в табл.1. Формат поля описания данных определяется по табл.2.
Структура области описания данных для файла уровня 3*
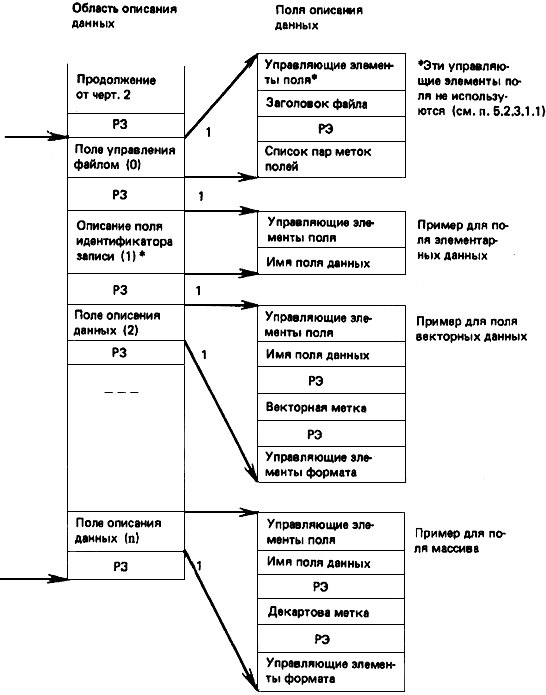
Черт.12
Таблица 2
Описатели составных полей данных
Структура данных: тип данных | Управляющие элементы поля | Имя/метка/управляющие элементы формата* | |
ОП | |||
0 1 2 3 | 4 5 | ||
Элементарная: | |||
символ | 0 0 0 0 | ['Имя']; | |
неявная точка | 0 1 0 0 | ||
явная точка | 0 2 0 0 | ||
масштабированный с явной точкой | 0 3 0 0 | ||
строка битов символьного режима | 0 4 0 0 | ||
поле битов | 0 5 0 0 | ['Имя'] & 'уэф'; | |
Вектор: | ['Имя'] & ['Векторная метка'] | ||
символ | 1 0 0 0 | ||
неявная точка | 1 1 0 0 | ||
явная точка | 1 2 0 0 | ||
масштабированный с явной точкой | 1 3 0 0 | ||
строка битов символьного режима | 1 4 0 0 |
| |
поле битов | 1 5 0 0 | ['Имя'] & ['Векторная метка'] | |
смешанный | 1 6 0 0 | ||
Массив: | ['Имя'] & ['Декартова метка'] | ||
символ | 2 0 0 0 | ||
неявная точка | 2 1 0 0 | ||
явная точка | 2 2 0 0 | ||
масштабированный с явной точкой | 2 3 0 0 | ||
строка битов символьного режима | 2 4 0 0 | ||
поле битов | 2 5 0 0 | ['Имя'] & ['Декартова метка'] | |
смешанный | 2 6 0 0 | ||
__________________
* Описание может быть прервано после любого подполя при помощи разделителя поля (1/14). Печатные символы в настоящем стандарте заменяют разделители информации, символы которых отсутствуют в некоторых устройствах печати. Пользователь может выбрать свои печатные символы для разделителей информации при условии, что они не будут вносить неоднозначность в содержание данных.
В поле описания данных могут быть описаны следующие типы данных:
Тип | Содержимое |
символ | строки символов |
неявная точка | представление чисел с неявной точкой |
явная точка | представление чисел с явной точкой, немасштабированное (фиксированная запятая) |
масштабированный с явной точкой | представление чисел с явной точкой, масштабированное (плавающая запятая) |
строка битов символьного режима | цифры 0 и 1 |
поле битов | двоичные цифры |
смешанный | один или более из вышеперечисленных типов данных |
В табл.2 применяются следующие синтаксические правила:
1) [ ] - определяет необязательность присутствия подполя;
2) 'имя' - определяет строку символов, идентицирующую поле в целом;
3) 'векторная метка' - определяет набор элементарных меток, который соответствует набору подполей в записях данных и имеет вид: метка 1! метка 2! ...;
4) 'декартова метка' - определяет набор меток, которые включают в себя векторные метки, образующие Декартово произведение, имеющее порядок, соответствующий набору подполей в записях данных, и принимает вид: метка 1! метка 2!...* метка а! метка b! ...*...;
5) 'уэф' - определяет управляющие элементы формата, которые состоят из строки символов, определяющих формат поля данных.
Чтобы избежать неоднозначности при неполном описании данных, требуется наличие следующих непосредственно друг за другом разделителей, указывающих на отсутствие имени, метки или формата.
6.2.2. Управляющие элементы поля
Управляющие элементы поля в позициях 0-5 состоят из четырех цифровых символов, за которыми следует два определенных пользователем печатных графических символа для представления разделителей информации 1/14, 1/15 в этом же порядке. Относительные позиции 0 и 1 должны интерпретироваться как код структуры и типа. Относительные позиции 2 и 3 резервируются для последующей стандартизации. Значение 00 в относительных позициях 2 и 3 означает, что никакое дополнительное управление не предусмотрено.
Примечание. Два выбранных пользователем печатных графических символа не должны встречаться в полях данных. Они также не должны заменяться разделителями информации ИСО (см. табл.1) в полях данных, так как вводятся дополнительно для облегчения визуального воспроизведения. Если дополнительный символ не определен, следует использовать по умолчанию символ пробела (2/0).
6.2.3. Имена, метки и управляющие элементы формата
Ниже описывается использование имен, меток и управляющих элементов формата.
6.2.3.1. Имя
Имя является необязательным заголовком для поля данных и его содержимого. В именах допускаются символы национального варианта или символы из набора по умолчанию, как определяется в п.7.1.
6.2.3.2. Метка
Метка является необязательным заголовком для элементарных полей данных. Там, где элементарные поля данных образуют вектор, метка должна иметь вид соответствующей векторной метки. Там, где элементарные поля данных образуют массив, метка должна иметь вид соответствующей декартовой метки, которая преобразуется в массив меток, соответствующий массиву данных. Векторные метки, входящие в декартову метку, представляют заголовки строк и столбцов соответствующего массива. Первая векторная метка декартовой метки может быть пустой (т.е. отсутствовать), при этом в описании двух- (и выше) мерного массива строки не будут поименованы. На наличие пустой первой векторной метки указывают расположенные подряд разделители (1/15) и (2/10). Для использования этой конструкции требуется формат, который описывает массив в виде строки. Допускается использование пустых индивидуальных меток в векторных метках при условии наличия всех разделителей (по п.6.2.4).
В метках допускаются символы национального варианта или символы из набора по умолчанию, как определено в п.7.1. Символы │!" и │*" являются специальными графическими символами, используемыми для разделения векторных меток, и не должны появляться в имени элемента данных в подполе векторной метки.
6.2.3.3. Управляющие элементы формата
Управляющие элементы формата определяют посимвольную или побитовую структуру поля данных. Управляющие элементы формата обязательны для данных типа поля битов и смешанных типов данных и необязательны для других типов данных, для которых отсутствие управляющих элементов формата указывает на данные, ограниченные разделителями. Управляющие элементы формата требуются для определения последовательности и типа подполей в поле смешанных данных или для определения ширины поля в полях без разделителей, или для определения разделителей пользователя.
Управляющие элементы формата ограничиваются разделителем элементов (1/15), а в случае последнего подполя - разделителем поля (1/14) и будут иметь вид
( { Y | mY | k (mY, ...),...},...)

Примечание. В управляющих элементах формата тип данных указывают прописными латинскими буквами.
{ } - обозначает, что заключенное в скобки выражение следует обрабатывать как единое целое при необходимости повторения и вложения;
| - означает выбор одного из выражений, разделенных этим символом;
(*) и (n) - спецификации ширины поля;
* - произвольный разделитель пользователя;
n - положительное целое число, определяющее ширину поля (см. п.7.6)*;
m, k - положительные целые числа, обозначающие коэффициенты повторения для следующего за ним типа или группы типов данных соответственно;
... - означает повторение предыдущего выражения.
Использование управляющих элементов формата подчинено следующим правилам:
1) порядок полей и их тип, определенные управляющими элементами формата, должен соответствовать полю данных, когда просмотр формата происходит слева направо, расширяя вложенные термы слева. Если поле данных не исчерпано, формат должен повторяться с левой круглой скобки последовательно до последней правой круглой скобки, исключая те скобки, которые используются для ограничения ширины поля, и применяя соответствующий коэффициент повторения, если таковой имеется. Если такая правая скобка отсутствует, управление форматом должно вернуться к первой левой круглой скобке спецификации формата;
2) Z - подразумевает ограничение подполей ЗД разделителем элементов (1/15) и, в случае последнего подполя, разделителем поля (1/14);
3) (*) - подразумевает применение произвольного символа в качестве разделителя пользователя для соответствующего подполя данных. Разделителем в последнем подполе поля данных должен быть разделитель поля (1/14).
Разделителем пользователя может быть национальный символ или символ из набора по умолчанию, как определено в п.7.1;
4) поля данных для l-типа, R-типа и S-типа определяют число в форме, определенной соответствующими стандартами на представление чисел. Поле R-типа может содержать полностью определенную числовую форму S-типа;
5) поля данных, содержащие данные в виде строки битов символьного режима (С-тип), описывают строки битов в виде последовательности символов "0" или "1", соответствующей цифрам в представленной строке битов;
6) поля битов фиксированной длины (В-тип со спецификацией ширины поля) должны быть определены форматом и не должны иметь ограничителей подполей. Ширина поля битов фиксированной длины задается в битах. Векторы и массивы, содержащие битовые данные фиксированной длины, должны иметь смежные подполя. Последний байт поля битов фиксированной длины или подполя, или ряда смежных полей битов фиксированной длины, или подполей должен быть дополнен справа двоичными нулями. Поле должно заканчиваться разделителем поля. Первое из ряда полей битов фиксированной длины должно начинаться на границе байта, а ряд полей битов фиксированной длины не должен иметь неявного повторения формата от левой скобки;
7) поля битов переменной длины (В-тип без спецификации ширины поля) определяются следующим образом:
Байт 0 | Байты 1...n | Байты (n+1)...m | |
Счетчик длины поля | Длина поля битов | Данные поля битов, содержащие двоичные цифры | Дополнение нулями до полного байта |
Счетчик длины поля представлен одной цифрой, указывающей число десятичных цифр в элементе формата "Длина поля битов". Длина поля битов представляет последовательность десятичных цифр, задающих длину поля битов в битах. Поле битов переменной длины должно начинаться на границе байта.
Примечание. Множество полей битов переменной длины (векторы и массивы) может определяться путем использования соответствующего формата, а поля битов переменной длины могут использоваться в полях смешанных данных.
6.2.4. Число элементов в векторах и массивах
Длина (число элементов) вектора определяется его меткой, использованием управляющих элементов формата или использованием разделителей. Размерность и длина массива должны определяться декартовой меткой. Декартова метка не должна состоять из единственной векторной метки, образованной единственным элементом, содержащим исключительно цифры и запятые.
Примечание. Если массив имеет фиксированную размерность и длину во всех записях данных, и декартова метка не требуется, то метку можно заменить описателем массива, состоящим из размерности массива, за которой следует длина каждого вектора, причем все разделяют запятыми.
При отсутствии декартовой метки или описателя массива полю данных ЗД должно предшествовать положительное целое число, определяющее размерность массива, а также набор целых положительных чисел, определяющий длину каждой размерности. Элементы описания массива должны быть ограничены разделителем элементов (1/15). Массив должен быть упорядочен в виде строки.
7. РАСШИРЕНИЯ НАБОРА КОДИРОВАННЫХ СИМВОЛОВ
7.1. Использование наборов кодированных символов
Настоящий стандарт требует использования Международной ссылочной версии по стандарту ИСО 646 (ГОСТ 27463) с 7- или 8-битным представлением для всех ведущих меток, статей справочника и управляющих элементов поля и формата, включая разделители информации. Символы национальных вариантов не допускается использовать в управляющих полях, за исключением имен, меток и разделителей пользователя. Ссылка на ИСО 2022 (ГОСТ 27466) дана для использования расширенных кодов в полях данных, разделителях пользователя, именах и метках. Использование расширений кодированных наборов символов, определенных в ИСО 2022 (ГОСТ 27466) как наборы символов по умолчанию, в полях данных, именах, метках и для разделителей пользователя должно быть ограничено наборами, имеющими последовательности АР2 размером в три или четыре символа, как указано в ИСО 2022 (ГОСТ 27466).
Примечание. Расширение набора символов по умолчанию может быть объявлено для файла или отдельно для каждого поля данных, как описано в данном разделе.
Внутри полей данных можно использовать наборы символов национальных вариантов и любой из символьных наборов С0, С1, Г0, Г1, Г2 и Г3, как описано в ИСО 2022 (ГОСТ 27466), без ограничения длины последовательности АР2.
Если расширенный набор Г1 указан как набор символов по умолчанию в 7-битном представлении, то поля разделителей пользователя, меток и имен должны начинаться с набора Г0, пока не появится управляющий символ ВЫХ для вызова набора Г1. Действие вызванного набора должно заканчиваться с окончанием поля.
7.2. Вызов наборов символов по умолчанию для полей
Для каждого поля набор символов по умолчанию, имеющий n-символьную последовательность АР2, вызывается посредством размещения в ЗОД ОП 17-19 символов (2/0) (2/1) (2/0) и увеличением длины подполя управляющих элементов поля на три байта.
Три дополнительных байта, следующие непосредственно за управляющими элементами поля ЗОД (см. табл.2), должны содержать последние (п-1) символов последовательности АР2 (где 4), используемых для определения расширенного набора символов для соответствующего поля данных. Символы из последовательности АР2 должны быть выровнены влево и, если необходимо, поле должно быть дополнено справа символами (2/0). Если для некоторого поля не определено расширение набора символов, то эти три байта должны содержать символы ПРОБЕЛ.
7.3. Вызов набора символов по умолчанию для файла
Набор символов по умолчанию должен вызываться для файла путем размещения последних (n-1) символов, обозначающих его n-символьную последовательность АР2 (где 4) в ЗОД ОП 17-19. Символы из последовательности АР2 должны быть выровнены влево и, если необходимо, поле должно быть дополнено справа символами ПРОБЕЛ (2/0).
7.4. Область действия расширенных наборов символов, используемых в полях данных любого файла
Символы из расширенных наборов символов можно использовать во всех полях данных всех файлов. Каждое поле каждой записи должно начинаться с символа, взятого из расширенного набора символов, указанного управляющими элементами поля или тремя символами в ЗОД ОП 17-19. Если внутри поля данных используются другие последовательности АР2, то их действие должно ограничиваться концом поля.
7.5. Использование наборов многобайтовых символов
Примечание. Наборы многобайтовых символов могут использоваться в полях данных (кроме полей В-типа), в именах полей, в векторных и декартовых метках и в полях разделителей пользователя.
Условия использования:
1) имена полей и метки записывают в указанном наборе по умолчанию. В именах могут использоваться другие последовательности АР2 и область их действия должна заканчиваться в конце подполя, исключая разделитель;
2) разделители (2/1) и (2/10) векторных и декартовых меток должны быть записаны в многобайтовом наборе;
3) если многобайтовые разделители используются в качестве разделителей пользователя, то они должны быть вызваны, и область их действия должна заканчиваться в пределах скобок используемого формата.
7.6. Ширина поля с расширенными наборами символов
Когда для использования расширенных наборов символов требуется наличие управляющих символов расширения АР2, ВХ, ВЫХ или других управляющих символов, ширина подполя должна быть указана посредством разделителей (см. пп.6.2.1, 6.2.3.3) и форматы фиксированной длины не должны использоваться.
ПРИЛОЖЕНИЕ А
Рекомендуемое
РУКОВОДСТВО ПО ПРИМЕНЕНИЮ
А.1. ОТОБРАЖЕНИЕ СТРУКТУР ДАННЫХ В СТРУКТУРУ ОБМЕНА
Использование настоящего стандарта предусматривает отображение внутренней или обрабатываемой структуры данных пользователя в структуру обмена. Структуру обмена можно классифицировать как совокупность иерархических структур в виде упорядоченного корневого дерева. В случае единственной, неповторяющейся структуры, структура обмена сводится к единственной логической записи. Затем задача сводится к отображению обычно используемых обрабатываемых структур в совокупность структур дерева.
Это отображение в большинстве случаев можно выполнить непосредственно, без потери информации о структуре. В других случаях направленные связи в исходной структуре требуется заменить численными значениями, посредством которых исходная структура может быть восстановлена. В качестве альтернативы исходную структуру можно свести к более простой эквивалентной форме, которую отображают в структуру обмена. Требуемую запись описания данных в машиночитаемой форме можно создать автоматически из словаря данных отправителя, логической схемы или другого автоматизированного описания данных.
Данное приложение рекомендует, что можно сделать, но не указывает как, поскольку это существенно зависит от методов реализации исходной системы.
Предполагается отображение следующих структур данных в структуру обмена:
1) последовательные;
2) реляционные;
3) иерархические;
4) сетевые;
5) индексные.
А.1.1. Последовательные структуры
Последовательные структуры состоят из повторяющихся элементарных полей. Поля структуры хранения можно отобразить либо в набор элементарных полей, либо в структурированные поля, что, очевидно, более соответствует требованиям обмена. Многократно повторяемые данные фиксированного формата должны быть размещены в виде строк массива, чтобы избежать чрезмерных затрат памяти. Можно воспользоваться преимуществом повторения форматов от левой круглой скобки до тех пор, пока не будет исчерпано поле данных. Таким же образом декартова метка может обеспечить повторяющееся описание данных в виде строк. Эту функцию реструктуризации можно легко сделать частью программы ввода. Следует отметить, что система первого уровня может иметь возможность получать и отображать структуры более высокого уровня на уровне поля, даже если она не может автоматически обрабатывать эти поля. Множество файлов данных, таких как главный файл и авторизованные файлы, могут быть отображены во множество файлов описания данных. Имена файла и полей содержатся в соответствующих полях ЗОД.
А.1.2. Реляционные структуры
Реляционные структуры (или плоские таблицы) можно отобразить в структуру обмена, преобразуя одно отношение степени n в логическую запись, с использованием множества полей или векторной структуры в одном поле. Несколько отношений можно преобразовать в несколько файлов описания данных, как требуется. Имена отношений и доменов передаются в соответствующих полях ЗОД.
Кроме того, можно восстановить и передать последовательную иерархическую форму, которая представляет исходную базу данных в ее нормальной форме.
А.1.3. Иерархические структуры
В принципе единичную иерархическую структуру можно отобразить в структуру обмена, используя одну логическую запись и соответствующее иерархическое описание. В реальной практике для структур большого размера это приводит к проблемам обработки и для отправителя и для получателя. Более практическое решение состоит в том, чтобы пометить каждый узел или соответствующий набор узлов, составляющих деревья приемлемого размера, как логический объект, преобразованный в единичную логическую запись. Связи, которые разрушаются в процессе такой обработки, должны быть заменены полем данных, содержащим связь величин, которую потом можно использовать для восстановления связи. Это поле данных содержит список уникальных идентификаторов логических записей, ранее связанных с каждым узлом. Могут быть перечислены либо предшествующие, либо последующие узлы. Многократное применение таких полей данных может быть использовано для сохранения многих классов связей, основанных на различных атрибутах баз данных.
Методы, определенные в данном стандарте, можно использовать для передачи совокупности деревьев в одной записи. Список пар меток полей ЗОД, последовательность прямого обхода и алгоритм обработки, изложенный в приложении С*, достаточны для создания соответствующего бинарного дерева.
А.1.4. Сетевые структуры
Сетевую базу данных можно разложить на ее реляционные копии и передать в виде набора отношений. Каждый тип записи, включая записи о связях, образует отношение, которое следует описать и передать в виде файла описания данных.
Структуры хранения, относящиеся к классу ориентированных графов, достаточно сложны, чтобы сделать невозможным их представление в иерархическом виде, если не прибегнуть к разрушению связей и не ввести списки идентификаторов логических записей (узел). Эти принципы идентичны принципам обработки иерархических структур, но алгоритмы обработки для восстановления должны обнаружить оборванные связи и действовать соответствующим образом.
А.1.5. Индексы
Индексы, включая цепочки или нити, образуют структурированную информацию о базе данных, которая зависит от средств реализации и не может быть непосредственно передана. Однако существует логический эквивалент, в котором системно-ориентированные указатели заменяются идентификаторами логических записей. Индекс атрибута базы данных можно отобразить в файл описания данных, где каждая логическая запись является реализацией значения атрибута и связанного с ним списка уникальных идентификаторов логических записей (или узлов), имеющих то же значение атрибута. Таким способом индексы можно описывать и передавать.
А.2. Руководство по контрольному применению
Для сохранения максимальных возможностей взаимообмена конкретные применения данного стандарта должны сохранять спецификации для ведущей метки, справочника и других средств управления и ограничиваться лишь изменениями в форматах полей данных. Конкретное применение предполагает варьирование кодированных наборов символов, структур и содержимого полей. Ниже даны рекомендации для обоих вариантов.
А.2.1. Наборы символов
Рекомендуется использовать ИСО 2022 (ГОСТ 27466) в качестве стандарта для расширения ИСО 646 (ГОСТ 27463). Использование ИСО 2022 (ГОСТ 27466) обеспечивает общие алгоритмы обработки расширенного набора символов.
А.2.2. Системы прикладного применения
Потенциальное соглашение об особенностях управления для конкретных прикладных применений первоначально имело в виду приспособить существующие стандартные применения, и новые реализации должны использовать соглашения настоящего стандарта для гарантии широкой базы взаимообмена.
Конкретные прикладные системы могут обеспечить полное внешнее описание для каждого поля или использовать некоторые типы данных настоящего стандарта. В любом случае конкретное применение должно помечаться путем использования частного управляющего символа в ЗОД ОП 9, выбранного из колонок 4-7 ИСО 646 (международная ссылочная версия по ГОСТ 27463). Такое применение гарантирует, что будущие расширения настоящего стандарта на нарушат частные соглашения.
Примечание. Если пользователям требуется новая структура данных, которая может широко применяться, они должны обращаться в ИСО/ТК 97 для расширения настоящего стандарта.
А.2.3. Ограничения на функциональные средства пользователя
Настоящий стандарт рассчитан на возможность его применения в усложненном обмене и допускает более сложные конструкции, чем те, которые могут потребоваться отдельным группам пользователей. В этом случае, а также, когда пользователь может быть достаточно уверен в области действия его группы обмена, ограничения на использование настоящего стандарта должны быть наложены таким образом, чтобы поддерживалась совместимость вверх. Таким образом, гарантируется обработка посредством полной реализации и может быть упрощена обработка внутри ограниченной группы пользователей.
Пользователь должен учитывать, что действуя таким образом, он может снизить свои возможности получения файлов обмена от отправителей, которые не приняли каких-либо ограничений. В этом случае, когда число обменов мало, пользователь ограниченного программного обеспечения сможет принять файл и обработать его в выходной файл, составленный из записей, содержащих поля данных. Эти записи могут быть далее переработаны в приемлемую форму с помощью конкретного прикладного программного обеспечения.
Если пользователь применят ограничения, которые вводят несовместимость вверх, то следует использовать указатель применения (ЗОД ОП 9) для указания системы, согласованной в частном порядке. Если пользователь хочет передать вспомогательную информацию, связанную с ограниченной системой, он должен сделать это в поле, связанном с меткой поля 0...2 ЗОД. Это поле может использоваться в тех же целях, что и запись ЗОД, и содержать информацию, включающую идентификацию ограничений.
Две общие области, в которых ограничения могут оказаться полезными, связаны с классом ЭВМ и языками ЭВМ. Далее рассматриваются основные направления установления приемлемых ограничений в этих областях и способы использования настоящего стандарта в условиях указанных ограничений.
А.2.3.1. Ограничения для малых ЭВМ
Настоящий стандарт разработан так, что посредством параллельной обработки логических полей (т.е. справочников, полей описания данных и полей данных), обходя каждое последовательно, можно снизить требования к памяти для хранения информации обработки. Максимальные размеры блока и записи можно найти в соответствующих полях меток файла. Кроме того, длина каждой логической записи доступна как управляющее слово, а размеры полей даны в справочнике каждой записи.
Если приведенной выше информации недостаточно, то группа пользователей путем частных соглашений может:
1) ограничить поля данных до полностью форматированных полей и передавать максимальные размеры поля и подполя, просто не используя средство повторения формата в целом (т.е. от самой левой круглой скобки). При сканировании формата во время обработки ЗОД можно определить максимальную ширину поля и подполя, а также максимальные размерности каждого вектора и массива;
2) для полей переменной длины, ограниченных разделителями, указать в поле 0...2 ЗОД, зарезервированном пользователем, набор максимальных значений ширины полей, выраженный в виде формата, который, если его проанализировать, даст максимальные размеры и размерности. Предлагается эту информацию строить как подсправочник с соответствующими полями, что дает возможность обрабатывать ее алгоритмами, подобными тем, что используются для обработки ЗОД;
3) заменить максимальные размерности для векторов и массивов на имя и декартову метку, соответственно.
Предлагается использовать поле 0...1 в ЗОД для обеспечения точной идентификации ограниченной группы пользователей. Анализ этого поля должен предшествовать дальнейшей обработке.
А.2.3.2. Языковые ограничения
Для пользователей, желающих упростить реализацию интерфейса с конкретным языком высокого уровня, могут быть предложены следующие ограничения частного порядка:
1) ограничить структуры и типы данных, допускаемые настоящим стандартом, до подмножеств, разрешенных рассматриваемым языком высокого уровня (например, ограничить интерфейс ФОРТРАНА до элементарных данных, векторов, массивов и подполей фиксированной длины);
2) имена и метки полей ограничить до таких строк символов, которые можно использовать для образования переменных имен в рассматриваемом языке. Конкатенацию этих строк можно использовать для порождения иерархических имен, если язык высокого уровня может их принять и использовать.
А.3. Уникальные идентификаторы
Для записи данных часто не требуются уникальные идентификаторы, так как для этой цели служат значения определенных полей или комбинаций полей, таких, как главный ключ реляционной модели данных. Тем не менее, логическая запись может представлять всю ту информацию, которая связана с объектом, однозначно идентифицируемым в базе данных. Уникальное идентифицирующее поле часто представляет ценность, в особенности если происходит последующее обновление. В тех случаях, когда должен обеспечиваться произвольный идентификатор, часто достаточно последовательных целых чисел. В других случаях, естественно, этой цели служит и может быть использовано поле данных. Где это возможно, желательно использовать элементарное поле, тем не менее структурированные поля, такие как двухэлементный вектор, также могут быть использованы. Это препятствует включению информации в другие поля данных, которые могут быть использованы для установления связи с другими элементами в рамках этого или других массивов данных.
Желательна сортировка, если должны использоваться ссылки на возможность представления на экране дисплея для обнаружения и исправления ошибок, для понимания файла обмена или для обеспечения слияния файлов по мере их получения. Там, где используются поля переменной длины, может потребоваться формирование файла, если файл должен сортироваться по порядку.
ПРИЛОЖЕНИЕ В
ПРИМЕРЫ ПОЛЯ ДАННЫХ
В.1. Общее
Настоящее приложение содержит несколько примеров полей описания данных и соответствующих полей данных. Так как число допустимых комбинаций структуры, типа, имен, меток и управлений формата очень велико, то дается только образец. Во всех примерах следующие печатаемые символы заменяют разделители:
; - разделитель поля (1/14);
& - разделитель элементов (1/15).
В.1.1. Элементы элементарных символьных данных
(ЗОД ОП 9 = (2/0); ОП 10-11 = 00)
Пример | Содержимое поля | |
ЗОД | ЗД | |
1 | АВТОР; | Федоров; |
2 | ВОЗРАСТ; | 24; |
3 | ВЫСОТА | 5.5; |
4 | ВЕС; | 2.45Е2; |
5 | СТРБИТ; | 010101; |
6 | Наименование журнала; | Проблемы МСНТИ; |
В.1.2. Элементы составных данных
(ЗОД ОП 9 = (2/0); ОП 10-11 = 06)
В.1.2.1. Элементарные поля
Пример | Тип данных | Содержимое поля | |
ЗОД | ЗД | ||
1 | Символ | 0000; &ИМЯ; | ДЖЕЙН; |
2 | Неявная точка | 0100; &ВОЗРАСТ; | 18; |
3 | Явная точка | 0200; GPA; | 3.46; |
4 | Масштабированный с явной точкой | 0300; &DIST; | +0.5Е+02; |
5 | Строка битов символьного режима | 0400; &СТРБИТ; | 010101; |
6 | Поле битов (фиксированное) | 0500; &ПОЛБИТФ&В(6); | (01010100); |
7 | Поле битов (переменное) | 0500; &ПОЛБИТП&В; | 16(01010100); |
8 | Символ | 0000; &ЖУРНАЛ; | Проблемы МСНТИ; |
В скобках указаны двоичные цифры.
В.1.2.2. Поля векторов
В.1.2.2.1. Вектор символов с разделителями, с именем и метками подполей
ЗОД 1000;&Почтовый адрес&Индекс!Область! Город! Улица! Фамилия;
ЗД 123456&Минская&Жодино&Я. Коласа21&Быков;
В.1.2.2.2. Форматированный вектор с неявной точкой, с именем и метками подполей
ЗОД 1100; &НАСЕЛЕНИЕ &1960!1965!1970!1975&(4(6));
ЗД 765432987345903231897654;
В.1.2.2.3. Вектор с разделителями, с явной точкой, с именем, но без меток
1) ЗОД 1200; &ЗЛАКИ;
ЗД 3.46&2.47&11.94;
2) ЗОД 1200; &Коэффициент поглощения кварцерных стекол;
ЗД 0.0026&0.0029&0.003&0.0043;
В.1.2.2.4. Форматированные смешанные векторы с именем и без меток (может также интерпретироваться как массив)
ЗОД 1600;&ДОМАШНИЙ СКОТ&& (А, (,), l (5), R (5));
ЗД СВИНЬИ, 0274437.46 БЫЧКИ, 1776447.84;
В.1.2.3. Поля массивов
В.1.2.3.1. Массив символов с разделителями, с именем и декартовой меткой
ЗОД 2000; &СВОЙСТВА&Золото!Натрий!Медь!*Плотность!Цвет!Активность;
ЗД Высокая&Желтый&Инертный&Низкая&Серый&Высокая&
Средняя&Красноватый&Низкая;
Эквивалентная таблица
СВОЙСТВА
Плотность | Цвет | Активность | |
Золото | Высокая | Желтый | Инертный |
Натрий | Низкая | Серый | Высокая |
Медь | Средняя | Красноватый | Низкая |
В.1.2.3.2. Форматированный массив с неявной точкой, без имени и без метки
ЗОД 2100; &&& (91 (2));
ЗД 2&3&3&124788334672441921;
В.1.2.3.3. Массив с разделителями, с явной точкой и с именем
ЗОД 2200; &ЕДИНИЧНАЯ МАТРИЦА;
ЗД 2&3&3&1&0.&0.&0.&1.& 0.&0.&0.&1;
В.1.2.3.4. Форматированный смешанный массив с именем и векторной меткой столбца, содержащий пустую векторную метку строки
ЗОД 2600; & Таблица; 11&*Металл! Плотность! Цвет! Активность&
(А(:), R (4), А (,), R (4)):
ЗД Золото: 14.8 Желтый, - 1.3 Натрий: 0.63Серый, 4.81 Медь:
10.6 Красноватый,. 043;
В.2. Использование расширенных наборов кодируемых символов
В.2.1. Кодированные наборы символов по умолчанию для полей
Использование кодированного набора символов Г1 по умолчанию для полей определяется установкой значений в позициях ЗОД ОП 17-19 и в расширенных управляющих элементах поля для каждого поля, как показано ниже:
1) позиции ЗОД ОП 17-19 содержат (2/0) (2/1) (2/0). Это означает, что отдельные поля могут содержать расширенные наборы кодируемых символов;
2) позиции ЗОД ОП 10-11 содержит "09". Это означает, что существуют 9 байтов, содержащих управляющие элементы поля, последние три из которых представляют собой информацию последовательности АР2;
3) управляющие элементы поля ЗОД, предшествующие имени поля, содержат структуру и тип данных, печатаемые разделители и информацию о последовательности АР2.
Ниже показано несколько примеров расширенных управляющих элементов поля для отдельных зарегистрированных наборов символов.
Наборы символов Г1 | Управляющие элементы поля | ||||||||
ОП | |||||||||
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
1) JIS Катакана | 0 | 0 | 0 | 0 | ; | & | (2/9) | (4/9) | (2/0) |
2) Итальянская графика | 0 | 0 | 0 | 0 | ; | & | (2/9) | (5/9) | (2/0) |
3) Шведская графика в именах | 1 | 0 | 0 | 0 | ; | & | (2/9) | (4/8) | (2/0) |
4) Расширение не используется | 0 | 0 | 0 | 0 | ; | & | (2/0) | (2/0) | (2/0) |
Поля данных в случаях 1) и 2) будут содержать неструктурированный текст, составленный из ИСО 646 (ГОСТ 27463) как набора Г0 и указанного набора Г1. В случае 3) поля данных будут содержать последовательности строк символов, разделенных ограничителями. В случае 4) представлены управляющие символы для полей, где не определен набор Г1.
Примечание. Во всех приведенных примерах ОП 8 содержит (2/0), так как в этих примерах используются трехсимвольные последовательности АР2. Если используются четырехсимвольные последовательности АР2, то могут присутствовать другие образцы битов.
В.2.2. Наборы символов по умолчанию для файла
Использование набора символов Г1 по умолчанию для файла в целом указывается путем размещения последних символов последовательности АР2 в ЗОД ОП 17-19.
Для вызова символов Немецкой графики, как набора по умолчанию Г1 для всего файла, ЗОД ОП 17-19 должна содержать (2/9) (4/11) (2/0).
Одно или более полей данных могут содержать в 8-битной среде коды высокого уровня и в 7-битной среде - управляющие символы ВХ и ВЫХ, изменяющие значения последующих комбинаций битов.
В.2.3. Встроенные расширения кодов
В полях данных могут свободно использоваться встроенные последовательности АР2. Получатель предупреждается о таком использовании содержимым ЗОД ОП 7. Символ Е (прописная латинская буква) означает, что будут найдены встроенные расширения кодированного набора символов, а символ ПРОБЕЛ означает, что встроенные последовательности АР2 не будут обнаружены.
Таким образом, в файле, содержащем встроенные последовательности АР2:
1) ЗОД ОП 7 содержит Е (прописная латинская буква) и
2) одно или более полей данных будут содержать последовательности АР2 - АР2 (I) (F), где (I) - один или более промежуточных символов и (F) - конечный символ последовательности АР2.
Эти последовательности АР2 не ограничиваются только набором Г1, но могут быть любой из последовательностей, допускаемых стандартом ИСО 2022 (ГОСТ 27466) как для 7-, так и для 8-битной среды.
ПРИЛОЖЕНИЕ С
Рекомендуемое
МОДЕЛЬ ФОД И СТРУКТУРА ЛОГИЧЕСКОЙ ЗАПИСИ
С.1 Модель ФОД
Чтобы сравнить модель ФОД с другими моделями файла, желательно описать структуру данных ФОД с помощью терминологии теории графов, т.е. в виде набора корневых упорядоченных деревьев. Каждое дерево соответствует логической записи. Корневой узел каждого дерева является полем идентификатора записи, который должен содержать уникальный идентификатор записи. Поля данных связаны с подчиненными промежуточными узлами дерева и с узлами-листьями.
Структуры дерева ЗД будут примером дерева, производного от общего дерева, описанного в ЗОД при помощи бинарных отношений и последовательности прямого обхода общего дерева. Конкретное дерево данных описывается бинарным отношением в ЗОД и последовательностью прямого обхода, требуемыми для конкретного дерева в ЗД. Структура дерева ЗД может быть незавершенной в том смысле, что могут отсутствовать узлы, которые предусмотрены ЗОД, но не содержат данных и не требуются для сохранения структуры. В дереве ЗД допускаются многие реализации поддерева ЗОД и идентификация обеспечивается порядком появления в последовательности прямого обхода.
Содержимое узлов - это данные, которые в свою очередь могут иметь регулярную структуру (т.е. элементарную, n- кортеж (вектор) или массив). Поля данных ЗД содержат единицы данных. Типы данных - это символы, три числовые формы, строка битов символьного режима и поле битов. Поля данных ЗД описываются форматами в ЗОД, а также поля данных могут содержать смешанные типы данных.
Иерархическая структура не является обязательной. Без нее файл - это собрание однозначно идентифицируемых логических записей, каждая из которых содержит набор поименованных (снабженных метками) полей данных. Поля в ЗД могут отсутствовать и можно использовать более одного примера поля, но связь их нельзя определять исходя из порядка полей. Эту форму можно рассматривать как одноуровневое корневое неупорядоченное дерево, где каждое поле неявно соединено с узлом идентификатора записи.
Одна из особенностей модели ФОД состоит в том, что благодаря требованию уникального идентификатора записи в качестве корневого узла каждого дерева весь набор деревьев можно выразить в виде одного упорядоченного дерева, корнем которого является ЗОД.
С.2. Иерархические логические записи
Этот раздел описывает средства, с помощью которых линейная структура помеченных полей может быть преобразована в иерархическую структуру. Иерархия или используемая структура упорядоченного корневого дерева имеет поля данных в качестве его узлов и направленные логические связи между содержимыми полей данных в качестве звеньев в структуре дерева. Корневое дерево имеет уникальный узел - корень, а каждый узел может иметь нулевое или большее количество упорядоченных поддеревьев. В конкретном случае структура дерева для записи может иметь несколько поддеревьев, образованных из множества случаев употребления полей данных, имеющих одну и ту же метку поля. Однако такое дерево может быть получено из (т.е. иметь те же логические связи полей) общего дерева для записи данных, где каждое поле содержится однократно и содержатся все возможные связи между полями.
Корневое дерево имеет направленные связи и только один корневой узел, который не имеет входящих в него связей. Каждый из остальных узлов может быть введен посредством только одной связи. Узлы, которые не имеют выходящих связей, называются узлами-листьями. Как только определен корневой узел, направление всех связей устанавливается от корневого узла до узла-листа. Иерархический уровень определен нумерацией корневого узла (1) и путем нумерации по возрастанию каждого последующего узла на всех путях к узлам-листьям. Деревья здесь изображены нисходящими от корня, причем поддеревья каждого узла упорядочены слева направо. Примеры упорядоченных корневых деревьев показаны на черт.13. Приведенное дерево не является бинарным деревом, которое сохраняет лево- и правосторонность в отсутствие одной бинарной ветви.
Примеры упорядоченных корневых деревьев
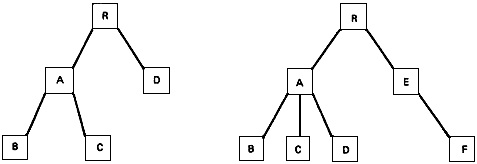
Черт.13
Метод, использованный здесь для представления структур корневых деревьев, тесно связан с точкой зрения пользователя на данные, а не с общепринятым машинным представлением древовидных структур, которое соответствует бинарному дереву (см. черт.14 и 16).
Метки полей служат в качестве идентификаторов узлов (т.е. полей данных). Структура дерева должна быть описана двумя частями информации:
1) упорядоченные пары идентификаторов узлов (меток полей) общей структуры в порядке сверху вниз от исходного к порожденному;
2) упорядоченный список идентификаторов узлов (меток полей) в последовательности прямого обхода.
Общая структура логической записи может быть деревом, как показано на черт.14
Общая структура логической записи
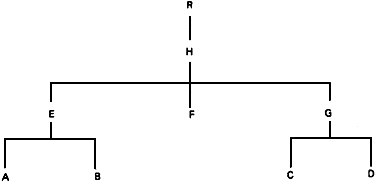
Черт.14
Она имеет набор упорядоченных пар меток полей RH, НЕ, ЕА, ЕВ, HF, HG, GC, GD, где R - метка поля уникального идентификатора записи, 0...1.
Последовательность прямого обхода меток полей этой структуры есть - RHEABFGCD и каждый узел употребляется однократно.
Характерный пример предыдущей общей структуры, имеющей множество случаев употребления полей данных с одной и той же меткой поля, представлен на черт.15, где R является меткой поля уникального идентификатора записи, а упорядоченные индексы (в скобках) для повторяющихся меток полей добавлены для ясности. Последовательность прямого обхода будет - RH(1) E(l) A(l) B(l) F(l) G(l) D(l) H(2) E(2) E(3) G(2) D(2) D(3) H(3) E(4) B(2) F(2) F(3), которую можно записать без индексов в скобках, не потеряв смысла. Отметим, что только корневой узел R уникален, а поля Н, Е, А и т.д. могут встретиться несколько раз, и в этом случае они обозначены повторением одной и той же метки поля.
Пример дерева данных пользователя
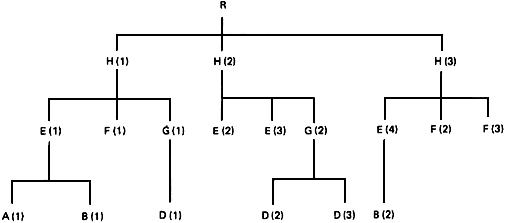
Черт.15
Последовательность прямого обхода обычно объединяется с информацией о связях, чтобы представить структуру дерева. В большинстве случаев используется соответствующее бинарное дерево. Это бинарное дерево имеет ту же последовательность прямого обхода, что и упорядоченное дерево, и связь с первым поддеревом узла образует левостороннюю связь в бинарном дереве, а все смежные узлы одного уровня соединены по порядку правосторонними связями между себе подобными. Эти новые связи легко выводятся из списка пар меток полей и последовательности прямого обхода. Пользователь может затем создавать все, что требуется его системе соглашением о связях.
Алгоритм, который образует лево- и правосторонние связи соответствующего бинарного дерева, приведен ниже, где общее дерево данного приложения использовано в качестве примера.
АЛГОРИТМ L. Дано, что P(q) является бинарным отношением на наборе узлов, q выражает направленные допустимые связи между узлами, a T(q) - последовательность прямого обхода дерева или группы деревьев.
Построить L и R векторы индексов в Т, выражающие лево- и правосторонние связи соответствующего бинарного дерева:
Примечание. "-Е" читать как "не элемент из" а "||" - как "соединяется с".
L0 [Инициализировать] | m |
n | |
S | |
L | |
R |
L1 [Установить стек на корневой узел] j1, S(l)
1
L2 [Установить индекс узла на корневой узел] i1
L3 [Продвинуть к следующему узлу] ii+1
L4 [Проверить на заполнение Т] if i > n end
L5 [Проверить парный узел стека и i-й узел] if Т (S(j)) || T(i) - Е Р go to L8
L6 [Запомнить левую связь для узла стека] L(S(j))i
L7 [Добавить i-й узел в стек] jj + 1, S(j)
i, go to L3
L8 [Проверить парный предпоследний узел стека и i-й узел]
if Т (Sj - 1)) || T(i) - Е Р go to L11
L9 [Запомнить правую связь для узла стека] R (S(j))i
L10 [Восстановить узел стека] S(j)i, go to L3
L11 [Вернуться к низшему узлу в пути] jj-1
L12 [Проверить узел на разрыв (новое дерево) ] if j=0 go to L9
L13 [Проверить повторную новую пару узлов] go to L8
Пример.
Р: | RH, | НЕ, | ЕА, | ЕВ, | HF, | GC, | GD, | HG, | |
j: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Т: | R | Н | Е | А | В | F | G | С | D |
L: | 2 | 3 | 4 | 0 | 0 | 0 | 8 | 0 | 0 |
R: | 0 | 0 | 6 | 5 | 0 | 7 | 0 | 9 | 0 |
Алгоритм действует для корневых ориентированных деревьев с или без повторяющихся меток полей в узлах. Он обрабатывает упорядоченный набор деревьев. Ветвь "истинно" в L12 может быть установлена на ошибку, если требуется ограничить обработку для деревьев.
На черт.16 представлено соответствующее бинарное дерево для упорядоченного корневого дерева, показанного на черт.14*.
Бинарное дерево, соответствующее корневому дереву, приведенному на черт.14*
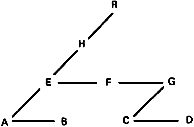
Черт.16
ПРИЛОЖЕНИЕ 1
Справочное
СПИСОК ОПЕЧАТОК И НЕТОЧНОСТЕЙ В АНГЛИЙСКОМ ОРИГИНАЛЕ
ИСО 8211-85
Пункт, чертеж | Напечатано | Должно быть |
П.5.1 последнее примечание | (see 7.1.4) | (see 7.5) |
Черт.2 | Не указана длина для поля "Base address of data descriptive area" | 5 |
Черт.2 и 12 | Data description of record identifier field | Description of record identifier field |
Черт.2 (стр. 5, ссылка на черт.12) и черт.12 (наименование) | level 2 | level 3 |
Черт.2 (стр. 6): заголовок; ведущая метка | . . . Data descriptive fields | . . . User data field |
Base address of data area | Base address of data area | |
Черт.4 (RP 12) | Base address of data | Base address of data descriptive area |
Черт.4 (RP 17) | Code character set indicator | Extended character set indicator |
П 5.2.1.2 | ... in clause 8 | ... in clause 0 |
... (see 5.2.3.1.2) | . . . (see 5.2.3.1.3) | |
П.5.2.1.7 | .. (see...7.1.3) | . . . (see...7.2) |
П.5.2.1.9 | . . . (see 7.1.1) | . . . (see 7.2) |
. . . (see 7.1.2) | . . . (see 7.3) | |
Черт.6 и 11 | - | i = 1...n |
П.5.2.3.1.1 (второе предположение) | ... title control field | ... file control field |
Черт.8 (наименование) | DR leader schematic | DR schematic |
Черт.9 (RP12) | Base address of data | Base address of user data area |
П.5.3.2.3 (третье предложение) | ... data descriptive area... | ... user data area... |
Табл.2 | Общий заголовок таблицы | Общий заголовок исключить Заголовок "Relative position" заменить на "Relative position of field controls" |
П.6.2.3.3 | ... (see 7.1.4) | ... (see 7.6) |
Приложение А, п.А.1.3 | ... of annex D | ... of annex С |
Приложение С, | ... in figure 15 | ... in figure 14 |
ПРИЛОЖЕНИЕ 2
Справочное
АЛФАВИТНЫЙ УКАЗАТЕЛЬ ТЕРМИНОВ НА РУССКОМ ЯЗЫКЕ И ИХ ЭКВИВАЛЕНТЫ НА АНГЛИЙСКОМ ЯЗЫКЕ
Термин | Пункт |
Базовый адрес данных | 4.3 |
Base address of data | |
Байт | 4.5 |
Byte | |
Буквенно-цифровой символ | 4.1 |
Alphanumeric character | |
Ведущая метка | 4.26 |
Leader | |
Векторная метка | 4.37 |
Vector label | |
Декартова метка | 4.6 |
Cartesian label | |
Длина записи | 4.32 |
Record length | |
Заголовок файла | 4.21 |
File title | |
Запись данных (ЗД) | 4.11 |
Data record (DR) | |
Запись описания данных (ЗОД) | 4.10 |
Data descriptive record (DDR) | |
Иерархия; иерархическая структура | 4.22 |
Hierarchy; hierarchical structure | |
Логическая запись; запись | 4.28 |
Logical record; record | |
Местоположение | 4.27 |
Location | |
Метка | 4.25 |
Label | |
Метка поля | 4.34 |
Tag | |
Описатель массива | 4.2 |
Array descriptor | |
Относительная позиция (ОП) | 4.33 |
Relative position (RP) | |
Отображать | 4.29 |
То map | |
План статьи | 4.17 |
Entry map | |
Поле битов | 4.4 |
Bit field | |
Поле переменной длины | 4.36 |
Variable - length field | |
Последовательность прямого обхода | 4.31 |
Preorder traversal sequence | |
Пусто | 4.30 |
Null | |
Разделитель | 4.13 |
Delimiter | |
Разделитель поля (РЗ) | 4.19 |
Field terminator (FT) | |
Разделитель элементов (РЭ) | 4.35 |
Unit terminator (UT) | |
Составное поле данных | 4.8 |
Compound data field | |
Справочник | 4.14 |
Directory | |
Статья справочника | 4.15 |
Directory entry | |
Строка битов в символьном режиме | 4.7 |
Character mode bit string | |
Структура с разделителями | 4.12 |
Delimited structure | |
Управляющий символ АР 2 | 4.18 |
Escape character, ESC | |
Уровень обмена; уровень | 4.23 |
Interchange level; level | |
Файл | 4.20 |
File | |
Файл описания данных (ФОД) | 4.9 |
Data descriptive file (DDF) | |
Формат обмена | 4.24 |
Interchange format | |
Элементарный | 4.16 |
Elementary |
Текст документа сверен по:
, 2006
